
Jeremy Davis
Sitecore, C# and web development
A while back I wrote a couple of posts on the subject of how code pipelines can work in a more functional .Net world. I've made use of those patterns in some code of my own, and I've found these posts have generated quite a lot of questions from readers here and followers on twitter. But I've never been quite happy with the implementation in my own code...
 url copied!
url copied!
Now the thing that didn't really fit here was that any attempt to fetch data over the internet can fail, but my original pipeline couldn't really handle that gracefully. You could either throw an exception that was caught outside of the pipeline, or you could include data in the pipeline's output model that specified what had gone wrong. But to my mind, neither of these is really the right way of solving the problem.
So how could you adapt the original pipeline model to better describe problems?
url copied!
For the sort of pipeline I'm thinking about for my RSS Reader, we're probably thinking about a pipeline that can return either a successful data object, or an error exception that occurred while the data was being processed. So the type looks something like:
public struct Either<SUCCESS, FAILURE>
{
private readonly bool _isSuccess;
private readonly SUCCESS _success;
private readonly FAILURE _failure;
public bool IsSuccess => _isSuccess;
public bool IsFailure => !IsSuccess;
public SUCCESS SuccessValue => _success;
public FAILURE FailureValue => _failure;
public Either(SUCCESS value)
{
_isSuccess = true;
_success = value;
_failure = default(FAILURE);
}
public Either(FAILURE value)
{
_isSuccess = false;
_success = default(SUCCESS);
_failure = value;
}
}
So we have a type that can store either a success or a failure, of whatever type is needed, and it's fairly simple. Now another thing that will be helpful for this later is to have some implicit conversions between the
Either
type and the two types it wraps. The conversion definitions aren't wildly readable to my mind, but to cast the object either way we need:
public static implicit operator Either<SUCCESS, FAILURE>(FAILURE value) => new Either<SUCCESS, FAILURE>(value); public static implicit operator Either<SUCCESS, FAILURE>(SUCCESS value) => new Either<SUCCESS, FAILURE>(value); public static implicit operator SUCCESS(Either<SUCCESS, FAILURE> value) => value._success; public static implicit operator FAILURE(Either<SUCCESS, FAILURE> value) => value._failure;
With that object in place, we need to re-define the basic pipeline step in terms of
Either:
public interface IErrorAwarePipelineStep<INPUT, OUTPUT, ERROR>
{
Either<OUTPUT, ERROR> Process(Either<INPUT, ERROR> input);
}
The pipeline steps are now defined in terms of their input and output types for the happy path, and their error type when something goes wrong. And the
Process()
function signature now has its inputs and outputs defined in terms of
Either.
And as before the overall pipeline is defined as having the same interface as an individual step, and having the set of steps collected together:
public interface IErrorAwarePipeline<INPUT, OUTPUT, ERROR> : IErrorAwarePipelineStep<INPUT, OUTPUT, ERROR>
{
Func<Either<INPUT, ERROR>, Either<OUTPUT, ERROR>> PipelineSteps { get; }
}
And we can have an abstract base to implement some reusable code for the overall pipeline too:
public abstract class ErrorAwarePipeline<INPUT, OUTPUT, ERROR> : IErrorAwarePipeline<INPUT, OUTPUT, ERROR>
{
public Func<Either<INPUT, ERROR>, Either<OUTPUT, ERROR>> PipelineSteps { get; protected set; }
public Either<OUTPUT, ERROR> Process(Either<INPUT, ERROR> input)
{
return PipelineSteps(input);
}
}
In the
previous implementation
we had a helper extension method to make composing the pipeline steps together. That also needs redefining in terms of
Either:
public static class ErrorAwarePipelineStepExtensions
{
public static Either<OUTPUT, ERROR> ErrorAwareStep<INPUT, OUTPUT, ERROR>(this Either<INPUT, ERROR> input, IErrorAwarePipelineStep<INPUT, OUTPUT, ERROR> step)
{
return step.Process(input);
}
}
Now for individual steps, the logic changes a bit in this model becauuse they now have to cope with two scenarios. The input to any step can be one of two things: Some happy-path data to process or an error state. That means each step needs to make a decision about which path it's going to go down, and since that's pretty standard logic it seems like a good case for an abstract base type for the steps:
public abstract class ErrorAwarePipelineStep<INPUT, OUTPUT, ERROR> : IErrorAwarePipelineStep<INPUT, OUTPUT, ERROR>
{
public abstract Either<OUTPUT, ERROR> ProcessSuccessInput(Either<INPUT, ERROR> input);
public virtual Either<OUTPUT, ERROR> ProcessErrorInput(Either<INPUT, ERROR> input)
{
return input.FailureValue;
}
public Either<OUTPUT, ERROR> Process(Either<INPUT, ERROR> input)
{
if (input.IsSuccess)
{
return ProcessSuccessInput(input);
}
else
{
return ProcessErrorInput(input);
}
}
}
The
Process()
method now just decides whether the input is a success or failure type, and calls the appropriate method on it. Most of the time I think the failure path will just "do nothing and pass on the existing error", so that can be a virtual method with this as default behaviour. But the opposite is true for the success path – pretty much every pipeline step will have some custom logic here, so it makes sense for that to be an abstract method.
And that's most of the basic logic we need to try this out...
url copied!
public class ErrorAwareStringToIntStep : ErrorAwarePipelineStep<string, int, Exception>
{
public override Either<int, Exception> ProcessSuccessInput(Either<string, Exception> input)
{
int value;
if (int.TryParse(input.SuccessValue, out value))
{
return value;
}
else
{
return new Exception("Can't parse string to integer");
}
}
}
So the step is defined in terms of taking in a string, returning an integer or returning an exception. It doesn't have any behaviour for the "failure" path, so no need to override that method, but the happy path can try to parse the string and return either the integer or the exception.
(And note that thanks to the explicit conversions we defined before, there's no need to explicitly cast the return values – the compiler sorts that out for us)
Another simple test component could multiply our result by a float to get a float result:
public class ErrorAwareMultiplyStep : ErrorAwarePipelineStep<int, float, Exception>
{
public override Either<float, Exception> ProcessSuccessInput(Either<int, Exception> input)
{
return input * 2.1f;
}
}
The other things we should try is to do something on the failure path. We can add happy path logic to do nothing, but override the failure path code to do something with the error data:
public class ErrorStateChangeStep : ErrorAwarePipelineStep<float, float, Exception>
{
public override Either<float, Exception> ProcessSuccessInput(Either<float, Exception> input)
{
return input;
}
public override Either<float, Exception> ProcessErrorInput(Either<float, Exception> input)
{
return new Exception("This is a custom exception", input.FailureValue);
}
}
In this case we're just trivially wrapping up the exception inside another exception – but it gives an indication of what can be done.
And with that in place we can then compose those components into a simple example pipeline:
public class ExampleErrorAwarePipeline : ErrorAwarePipeline<string, float, Exception>
{
public ExampleErrorAwarePipeline()
{
PipelineSteps = input => input
.ErrorAwareStep(new ErrorAwareStringToIntStep())
.ErrorAwareStep(new ErrorAwareMultiplyStep())
.ErrorAwareStep(new ErrorStateChangeStep());
}
}
So our pipeline will now take a string and give us back either a float or an exception, depending on what happens...
Now something else I realised when I started to try and set up some code to test out this example pipeline was that it would be helpful to have an easy way to process the result based on whether the
Either
represents success or failure. So stealing another pattern from the Functional world, I added a
Match()
method to
Either
which you pass a function to for success or failure:
public T Match<T>(Func<SUCCESS, T> successFn, Func<FAILURE, T> failureFn)
{
if(_isSuccess)
{
return successFn(_success);
}
else
{
return failureFn(_failure);
}
}
And that allows us to write a simple test where we can call the test pipeline defined above with a set of test data to see what happens:
public class Program
{
private static IErrorAwarePipeline<string, float, Exception> _pipeline = new ExampleErrorAwarePipeline();
private static void runPipeline(string input)
{
Console.WriteLine("Running pipeline:");
var result = _pipeline
.Process(input)
.Match(
f => $"Success: Transformed {input}[{input.GetType().Name}] to {f}[{f.GetType().Name}]",
f => $"Error: Transformed {input}[{input.GetType().Name}] to {f}[{f.GetType().Name}]"
);
Console.WriteLine(result);
Console.WriteLine();
}
private static void Main(string[] args)
{
runPipeline("27");
runPipeline("0");
runPipeline("0.1");
runPipeline("hello");
}
}
Which gives the expected results:
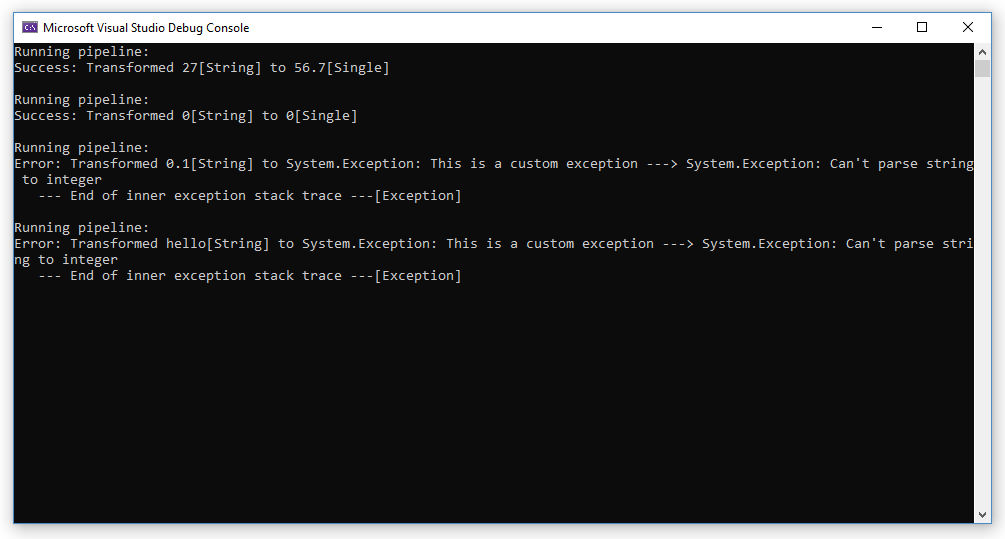
Where the pipeline can successfully process the input, the result is the expected data. And where it can't we get an exception wrapped up in the way the final component specified...
The code for this is available in a gist if you want it all together.
url copied!
But the counterpoint to that is that the interfaces of the various types involved in the pipeline infrastructure got more complex, and less readable as a result. And I'm not sure I've got to the bottom of the set of type casts and helper methods necessary to ensure that it's easy to use
Either
in the midst of other code.
But I'm pretty sure Functional developers have already solved those problems – I just need to work out what the rough edges I need to sort out are. And to be sure of what they are I need to write some more code using this pattern...
↑ Back to top
