
Jeremy Davis
Sitecore, C# and web development
One of the interesting things that's arrived with Sitecore v10.1 is a new approach to how items get updated when you change versions. This change is aimed at containerised deployments, and I'm in the middle of a containerised project. So I figured I should take a look...
 url copied!
url copied!
SELECT * FROM [Sitecore.Master].[dbo].[Items]
You'll see a surprisingly small result set:

Two rows? What happened to all the items records? Because when you look in the content tree, it all looks pretty normal:
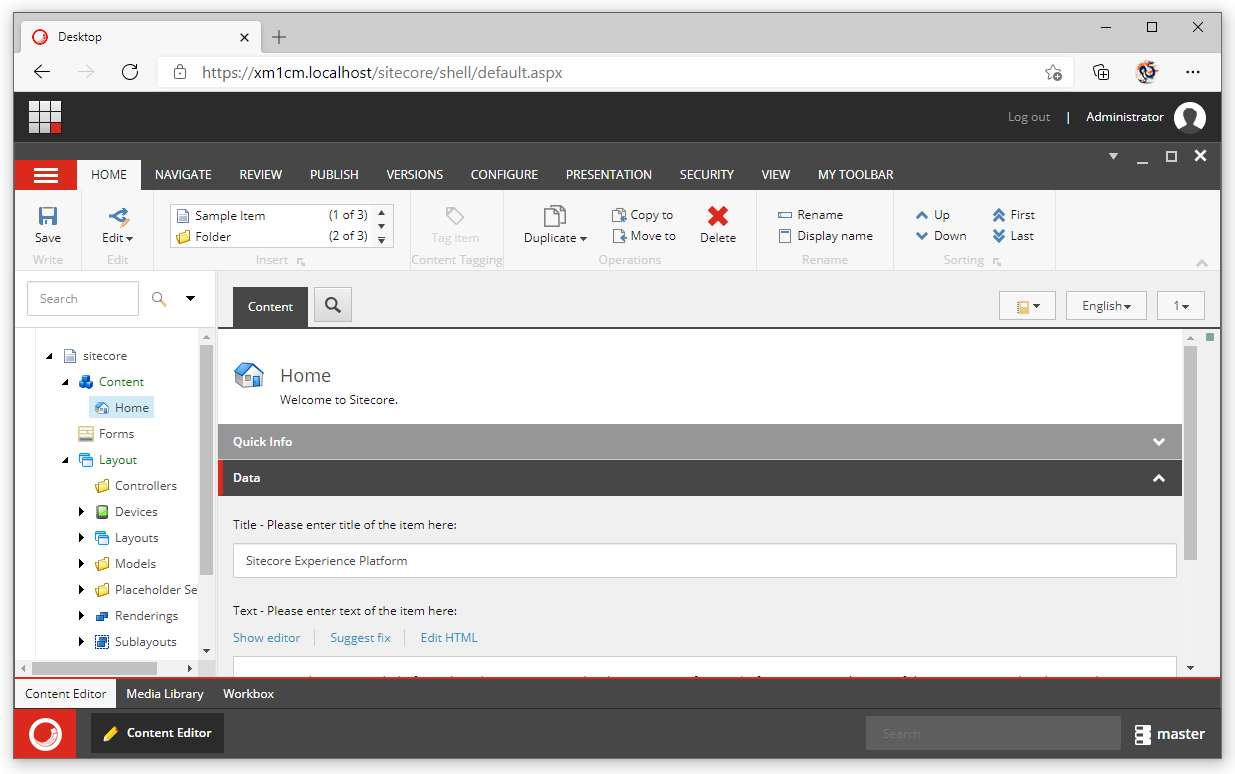
There's certainly more than two items there, so what's going on? How come there appear to be items in the content tree, when the database looks empty?
url copied!
In a vanilla copy of Sitecore v10.1 you'll find the following new folders and files in the website:
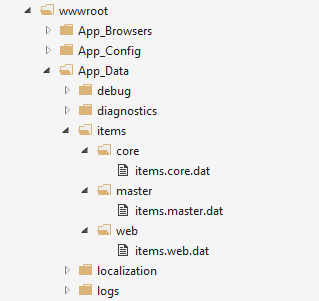
And if you look into the config for this release, you'll see that your database definitions have changed a bit. For example, the master database's configuration now includes this:
<database id="master" singleInstance="true" type="Sitecore.Data.DefaultDatabase, Sitecore.Kernel" role:require="Standalone or Reporting or Processing or ContentManagement">
<param desc="name">$(id)</param>
...
<dataProviders hint="list:AddDataProvider">
<dataProvider type="Sitecore.Data.DataProviders.CompositeDataProvider, Sitecore.Kernel">
<param desc="readOnlyDataProviders" hint="list">
<protobufItems type="Sitecore.Data.DataProviders.ReadOnly.Protobuf.ProtobufDataProvider, Sitecore.Kernel">
<filePaths hint="list">
<filePath>$(dataFolder)/items/$(id)</filePath>
</filePaths>
</protobufItems>
</param>
...
</dataProviders>
...
</database>
The database has a new data provider type –
CompositeDataProvider. It's job is to provide a merge between what's in those disk files and what's in the database. You can see that under the
<dataProvider/>
element that there is some xml describing where to look for the files, based on the id of the database.
The key reason for a merge operation is that if you edit an item that's stored on disk, the resulting changes will get saved in the database. And from then on it's the database item that gets presented back to you in the UI. So the database takes priority. As an example, if I got to
/sitecore/content
and click the "unprotect" button in the UI, that item gets updated, and hence appears in the database because of this change:
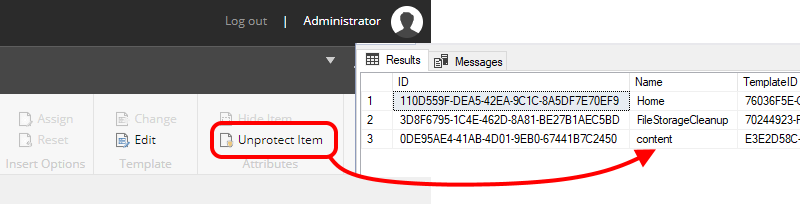
Edited to add: As brought up in the comments, the other side-effect of this model is that you cannot delete items which exist in resource files. You get (an amusingly typo'd) error dialog saying "Some of selected items are in resources and cannot be deleted".
url copied!
In fact, you can have a peek inside these files if you fancy. As a very simple experiment, I tried extracting the tree-structure of what's inside the "web" file. Starting from a .Net v4.8 Console App project, I added the nuget package for Sitecore.Kernel v10.1 – that gives you both the ProtoBuf.Net library and some internal types for representing the data.
The code starts by taking the path of one of the binary files, opening it as a simple stream and then running the ProtoBuf deserialiser over it. The top level type for this data is the new
Sitecore.Data.DataProviders.ReadOnly.Protobuf.Data.ItemsData
class, which is specified as the type parameter to the deserialiser. And once we've got that data, we can look for an item who's parent is the empty guid. That will be the root of the tree, and we can start processing the data for display from there:
public void Process(string filePath)
{
using (var fs = File.OpenRead(filePath))
{
_data = Serializer.Deserialize<ItemsData>(fs);
var root = _data.Definitions.Where(i => i.Value.ParentID == Guid.Empty).Select(i => i.Value).FirstOrDefault();
Process(root);
}
}
There are a few fields in that
ItemsData
class, and you can see it's decorated with serialisation attributes to control how the ProtoBuf encoding works:
[ProtoContract]
public class ItemsData
{
[ProtoMember(1)]
public ItemDefinitions Definitions { get; set; }
[ProtoMember(2)]
public ItemsSharedData SharedData { get; set; }
[ProtoMember(3)]
public ItemsLanguagesData LanguageData { get; set; }
}
And from there you can recursively look down the tree by following the ParentID pointers:
public void Process(ItemRecord item, int indent = 0)
{
var space = new string(' ', indent);
Console.WriteLine(space + item.Name);
var children = _data.Definitions.Where(i => i.Value.ParentID == item.ID).Select(i => i.Value);
foreach(var child in children)
{
Process(child, indent + 1);
}
}
For each item, print it's name with the right number of leading spaces for the current indent level, and then process each of it's children. If we wrap those methods up in a class and run that against one of the disk files:
var v = new Viewer(); v.Process(@"D:\myfolder\app_data\items\web\items.web.dat");
Then we see something that looks like the content tree:
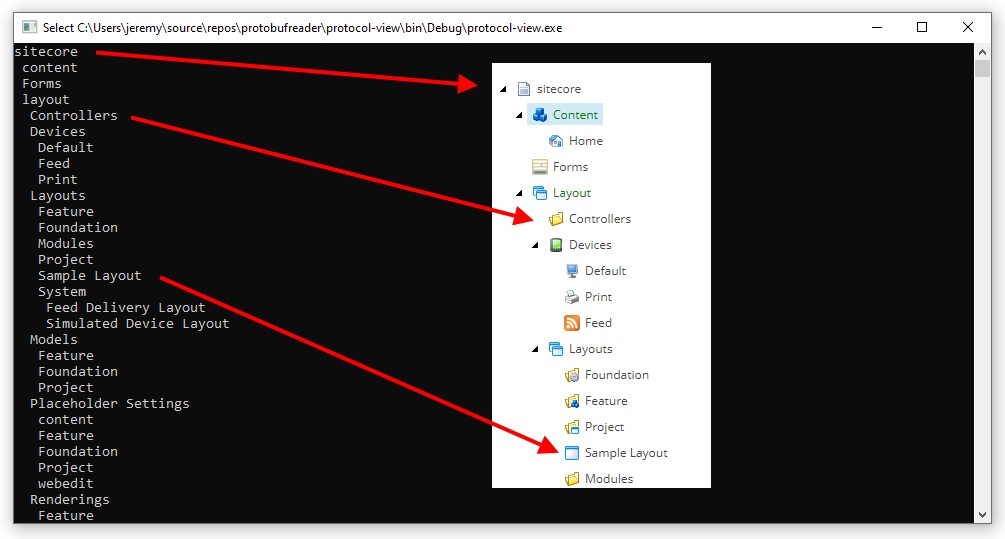
And with some more effort (and decoding the logic via ILSpy) we could extract item versions and field values from this data too:
url copied!
But in the world of containers we no longer need a package to give us the code and config changes for new Sitecore versions – those all come wrapped up into Sitecore's Docker Images. And we layer our custom code and config on top of these for release. But in container world, we do still need to do something else to apply the database changes.
That could be a "job" image. When you run these images they do a task and then stop – so you could put the database upgrade tasks into an image like this and let it run once against your SQL databases. That's pretty much the approach that is provided for initial setup of Solr and your databases with V10.0. So you could use this tactic to do upgrades too.
But Sitecore are trying a different tactic for the upgrade process now. Rather than having to make arrangements to run a job image once for each upgrade, they've moved these items into disk files which are automatically changed when you deploy the new Sitecore images. So any upgrade-related changes are magically merged into your content tree just by changing to the newer CM/CD images.
And there's the potential for another advantage here. The logic that loads up the data from the disk files has a "merge" operation built in. So you could have multiple files in your "master" or "web" folders which all get loaded up on start-up. And that makes for an interesting approach to delivering modules. Historically we've always had to install packages (or deserialise items) to push the content items for our modules into a deployment. But if we serialise them into ProtoBuf files the item data could be merged into our Docker images without needing to touch databases. That fits really well with the patterns for building custom images for deployments – you could get a "Sitecore PowerShell" image which contains the code, config and ProtoBuf data to add the software to a basic Sitecore image, and your custom image build just has to use that image as a source and copy in the files.
So this approach looks like it could help us a lot in the future, and I find myself wondering if it might be a replacement for the TDS / Unicorn aspects of client builds eventually...
Edited to add: On Twitter, Kamruz Jaman points out something I'd entirely missed from the description above: Since we suddenly have many fewer rows in our content databases, publishing operations are much faster. There's no need to ever publish an item that's in the ProtoBuf data – because that's on both your CM and CD boxes. So publish only has to read the database rows that are left. Hence a "republish all" operation now has vastly less data to process – and is going to finish much faster.↑ Back to top

