
Jeremy Davis
Sitecore, C# and web development
One of the side-effects of being pretty old, and having been around The Internet for some time is that every so often I get to be the Old Man Shouting at Clouds over things I think went wrong along the way. (Or "progress" as people sometimes call it) And one thing that's really struck me recently is how Blogs have changed in recent years...
There's a big old rant I've got saved up about how so little modern content still provides good RSS feeds. But a more practical issue is that as most internet writing has moved away from the classic blogging platforms like Wordpress or the like these days. And one feature that the traditional blogging platforms provided was Trackbacks (or Pingbacks) - a mechanism that allowed my blog posts to know when someone else had cited it. They offered a standard API which other blog posts could call to say "I link to you" and they could store that data in their content database.
But modern static blogs don't have an easy way to host API endpoints and databases, so that concept is missing from many modern blogs. So is there a way this could work for them?
 url copied!
url copied!
In one of those "ah-ha!" moments when I was doing something entirely unrelated, I started wondering if I could use Google to help with this. If my static site can't actually receive messages when someone links to me, why not go searching for those links at build time and incorporate that data when the site is generated? For each post page that is generated by Statiq for my blog, it could perform a "what links to this url" query and render the results as a list of links on the page.
It seems like a plausable approach, so how can it work?
url copied!
The first challenge here is how to run a query from code. So I fired up Linqpad to have a play...
Without thinking too hard, the first approach you might consider is to make an HTTP request to Google's search page direct from code. If you do a search in your browser, you end up with a url that includes your query (like
https://www.google.com/search?q=law) so it seems likely that you could call that and parse out some results. But it turns out this isn't a great approach for two reasons. Firstly, there's a lot of cookie and permissions stuff that goes on when you browse like this. (Try a query in an InPrivate window, and have a look) While it's entirely possible to manage that in code, it's a bit of a hassle. And secondly Google don't like you doing this, because in their eyes this is dubious behaviour.
From Google's perspective the right answer is to use a separate approach to querying - they offer a developer-focused API called "Custom Search JSON API" to use. This gives a JSON endpoint which can return web or image search results without any of the consent, cookie or parsing challenges of trying to automate the main search page.
Since this API is part of the official set of Google Cloud endpoints, there's a bit of setup required however. First, you have to set up a programmable search "engine" by configuring some settings and getting an ID to pass which referrs back to those settings. That's done via the programmable search control panel ui where you can click "Add" and provide the settings. The key things here are what sites are being searched (to find any links, it shouldn't be restricted to a particular site) and the value of the "search engine id" field - which is required to make calls.
The second thing is that you need an API Key. There's a "get my key" option in the docs page linked above, which helps create/fetch this:
With those two things set up, a call is pretty simple. You need an HTTP GET call to
https://www.googleapis.com/customsearch/v1?key=<API Key>&cx=<Search Engine ID>&q=<Query>
with the right values substituted in. And the response will be a JSON document
following a standard schema. And that can be de-serialised to process it.
url copied!
Well the code needs to know the search engine ID and the key:
string engineId = "xxxxxxxxxxxxxxxxx"; string apiKey = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx-xxxxxxx";
And that can be used to generate the URL for a query:
var query = "<the query goes here>";
var url = $"https://www.googleapis.com/customsearch/v1?key={apiKey}&cx={engineId}&q={query}";
That query can be run, and the data can be returned:
HttpClient c = new HttpClient(); var json = await c.GetStringAsync(url);
With that json data, the results can be deserialised:
var serializeOptions = new JsonSerializerOptions { PropertyNamingPolicy = JsonNamingPolicy.CamelCase };
var results = JsonSerializer.Deserialize<GoogleResultSet>(json, serializeOptions);
The options there are just used to allow mapping the camel-case names in the json to the C# property names below. You could do the same with
JsonPropertyName
attributes, but this approach makes for shorter code examples.
Looking at the schema linked above, some classes to represent the data might look like these. The
GoogleResultSet
models a page of results in the
Items
property and the pagination data in the
Queries
object. If that has a value in
NextPage
then there is a subsequent page of results to fetch, and the
NextPage
data holds the parameters to use in the query. (The
StartIndex
value needs adding to the query URL using the
start
parameter)
public class GoogleResultSet
{
public GoogleResult[] Items { get; set; }
public GoogleRequestState Queries {get;set;}
}
public class GoogleResult
{
public string Title { get; set; }
public string Link { get; set; }
public string Snippet { get; set;}
}
public class GoogleRequestState
{
public GoogleRequest[] Request { get; set; }
public GoogleRequest[] NextPage { get; set; }
}
public class GoogleRequest
{
public string Title { get; set; }
public string TotalResults { get; set; }
public string SearchTerms { get; set; }
public int Count { get; set; }
public int StartIndex { get; set; }
public string InputEncoding { get; set; }
public string OutputEncoding { get; set; }
public string Safe { get; set; }
public string CX { get; set; }
}
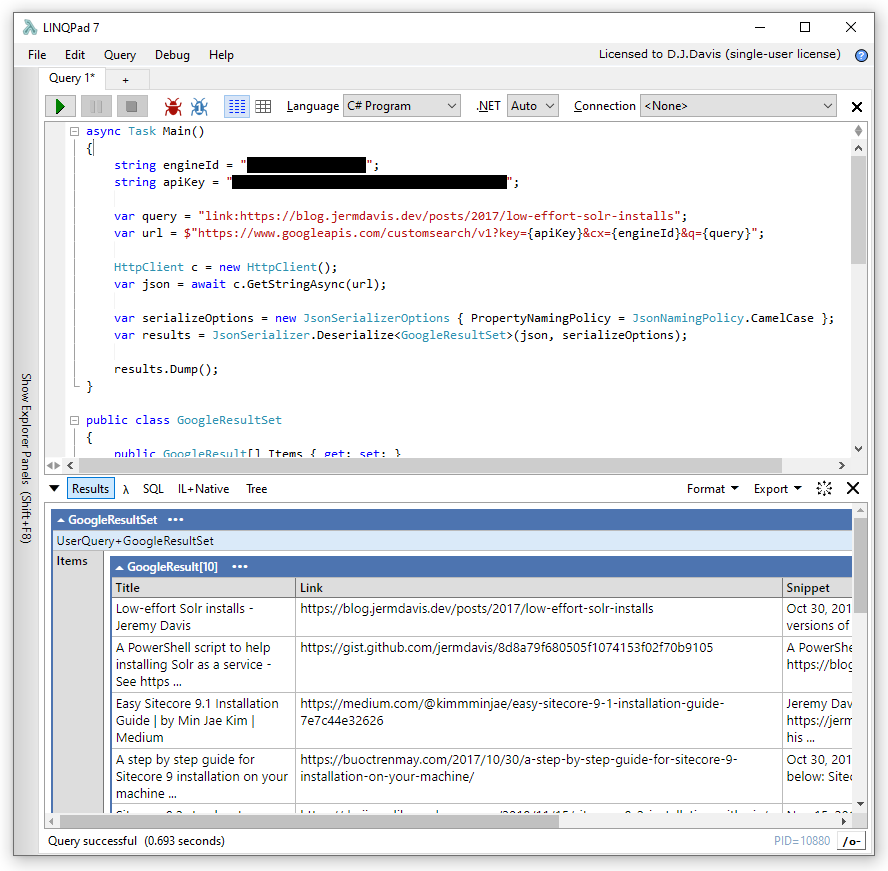
So that's the core code needed to fetch a set of results, and it's not too complicated. Running it generates data that looks plausible:
url copied!
Now this is an interesting question. Back in the day, Google supported a
link:<url>
operator that would return results which linked to the url specified. Officially that was depreciated back in 2017, and it's part of
a set of operators which sort of work but aren't considered reliable.
Running a query with this code using the operator does return some valid results, but also some which clearly do not link to the specified page. For example this query returns about 120 results, where some are relevant but some (like this one) relate to solr but not the link that was being queried. (Numbers are based on what I saw while writing this, btw - they may be different for you)
The alternative is a straight query for the URL of the page in question. A search with the url in quotes seems to return only the page in question. And the same query without the quotes returns about 60 results. But again these results include valid hits for a link to the specified URL as well as links which do not include it.
url copied!
I spent a while playing with this, doing some more googling and trying to come up with ideas here. But it doesn't seem to be possible to run a query for "give me only pages which include a link to <url>" any more. You either end up with a query so specific it does not return the right results, or one which includes a load of stuff which is more "Inspired by" the link specified than connected to it.
So maybe this would have to be a "maybe-related posts" module rather than trackbacks, alas.
It might be possible to further filter these results? The code could load the HTML for each result and check to see if it does include a link to the relevant page. That would likely increase the quality, but at the expense of speed as loading each one would add up over the course of generating the full site. Plus filtering would depend on the idea that the result set gave all the correct results, plus some extra ones. Filtering that would give the right answers. However if the results don't include some of the right answers then filtering isn't going to fix that.
url copied!
And there's another significant challenge here which I didn't realise when I started thinking about this:
Google rate-limit their programattic query API. You're allowed 100 queries per day free, and then have to pay for further queries. Given this blog has more than 250 posts already, that would make generating the site cost money - particularly as I often find myself generating pages multiple times while I try to get stuff right. I could imagine some sort of "cache the data from these queries" approach, which would re-query as many as possible for free on each rebuild. But that would be another big chunk of code, and it would mean the data was pretty much guaranteed to be out of date, as it would take three days to do the queries for all the pages without incurring fees.
So I don't think I'll be rolling this idea out. Too many negatives, despite me really wanting the data back.
I'm now w
↑ Back to top
