
Jeremy Davis
Sitecore, C# and web development
I wasn't at SUGCON**1 this year, but I followed the event on Twitter and have read a few of the write-ups that have been posted since the event. A popular topic this year has been applying machine learning to Sitecore in the quest for ever cleverer personalised experiences. It's fascinating stuff to read about, and I'm sure it has great potential for the future, but what I didn't see much discussion of was the possible down-sides of using "AI" for these tasks rather than people making choices. So allow me to put on some comedy horns and play devil's advocate for a bit...
 url copied!
url copied!
Spy satellites and surveillance aircraft take loads of reconnaissance photographs every day. Interpreting these photographs is a skilled job – filtering out the pictures which show important things, tracking movements of your enemy's resources and trying to spot the pictures which show deliberately fake things like decoy tanks. And this sort of repetitive but skilled job seems idea for automation...
As a first step in automating the analysis, one organisation tried using a machine learning system to filter out the pictures which showed enemy tanks – in the hope that this could allow the expert humans to focus on just the pictures that were really of interest to them. The developers of the system gathered up a large collection of existing images, some showing tanks and some showing none, and they set to work training their computer. When the model was refined they were able to reliably sift the test data into the required two groups.
So they moved on to trying to classify new photos as they were being taken. This did not go at all well. When presented with the "live" data, the system's accuracy fell to less than 50%. The project team were baffled – how could their system work so well with the training data, but fail so badly with real data?
They spent a lot of time examining what had happened, before finally realising their mistake: By accident there was a subtle correlation in their test data between "images that contained tanks" and "images taken when the sun was high in the sky". What they'd actually managed to do was teach their system to spot "images taken around lunchtime" based on what the shadows looked like...
This sort of unintended consequences of machine learning is an important thing for us to think about before we automate our choices of images in content, or our personalisation decisions. Machine learning systems are complex, and can sometimes seem like a magic black box. When you think about our traditional Sitecore approach to rules-based personalisation to choose content, the outcomes of a system like that are obvious. You can see the choices the computer might make on screen, and the logic the system will use to arrive at it is human-readable. But that is often not the case with a machine learning system – the choices are wrapped up in "fuzzy sets" or "tensor algorithms" which those of us without advanced mathematics knowledge don't really understand.
The challenge of "not understanding why the computer will make a certain decision" is also an issue that's quite hard to guard against once you're trusting the computer to make choices for you. Fundamentally there are some things which computers find easy to do better than humans, and there are some things where they struggle much more. Crunching vast quantities of numbers to win at complicated games like Go is something modern computers can do reliably. But, as twitter pointed out to me recently, getting them to tell the difference between dogs and muffins is much harder:

Much like the shadows around tanks, human brains instinctively arrive at the right answer when looking at pictures like this – but it's a big challenge for a computer to know what the right answers are. And without thinking about it, we're actually making much more complex decisions when we're choosing content for web pages. As well as picking out images which contain the right things, we're also filtering out images that might be partially right but could have bad implications when thought about in different ways. If the fruit in the muffin was arranged into a rude shape, we'd spot that instinctively, but the computer would not think outside the "is it a dog or a muffin?" box...
(Another hilarious but somewhat NSFW example of how computers are less flexible than the human mind is the story of why the original Lego MMO failed under the costs and issues of being unable to correctly automate user-generated content filtering to make it safe for children)
We can already see some of the issues this raises in the world of advertising. You've probably seen comments online about how some major buyers of advertising space on the internet are frustrated by Google placing their adverts next to inappropriate content on YouTube. And the problem of computers making poor choices of what adverts to show next to content is so pervasive that the UK satirical magazine Private Eye runs a recurring column pointing out poor choices their readers have spotted:

It's easy to laugh at these things – but they do have the potential to do harm to brands...
url copied!
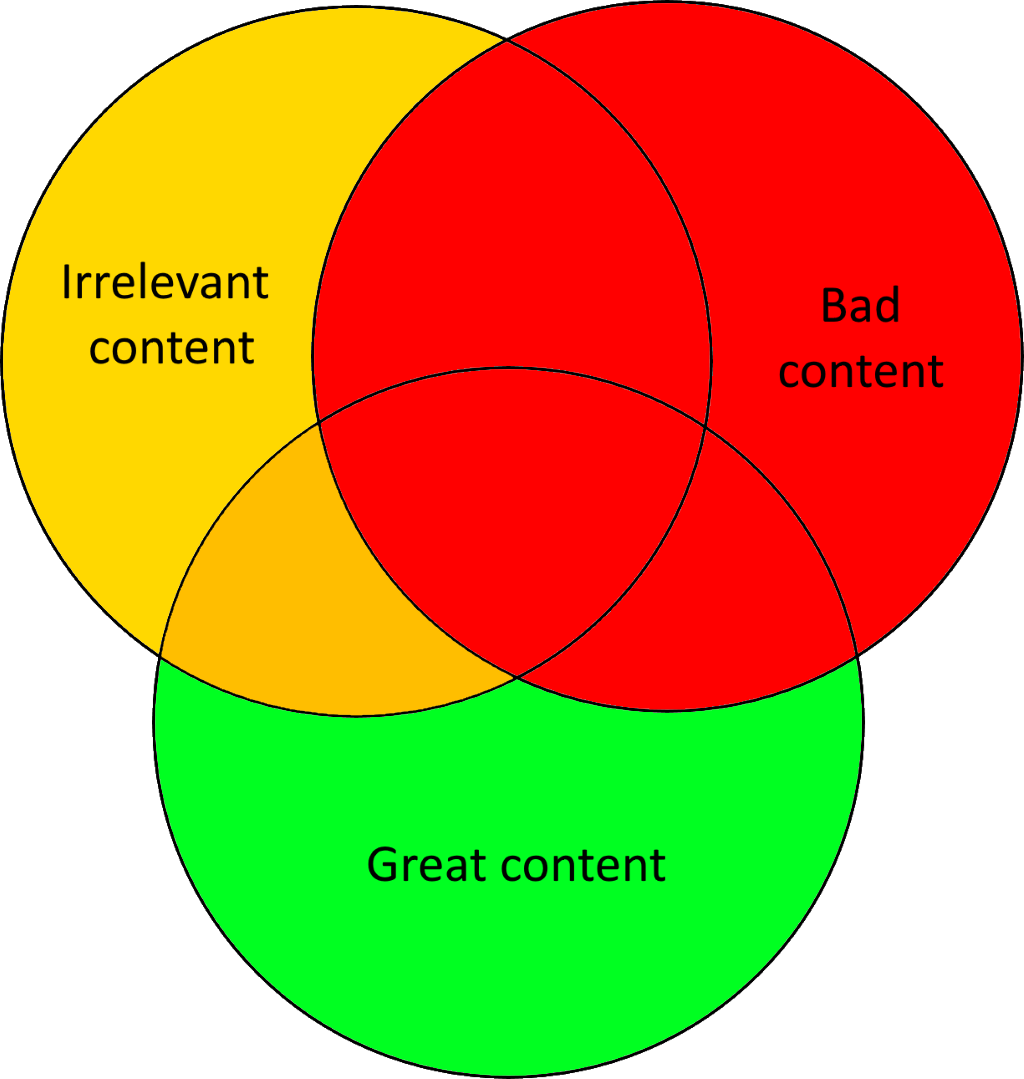 In situations where we want to leave the computer to make decisions for us, the most successful options in the production of website content are likely going to be those where they make automated choices from a pool of data that humans have already examined. Thinking about a venn diagram of all the content the site could present, it's easy to see that if we can remove the inappropriate red content before the computer makes its choices then we're much less likely to suffer brand problems or comedy mistakes. What the computer can focus on is trying to ensure that whatever it presents comes from the green region for each individual user, and try to avoid the orange. And hopefully that's the sort of choices where the machines can do a good job without major risks. But of course you do need more editorial resources to run a system like this.
In situations where we want to leave the computer to make decisions for us, the most successful options in the production of website content are likely going to be those where they make automated choices from a pool of data that humans have already examined. Thinking about a venn diagram of all the content the site could present, it's easy to see that if we can remove the inappropriate red content before the computer makes its choices then we're much less likely to suffer brand problems or comedy mistakes. What the computer can focus on is trying to ensure that whatever it presents comes from the green region for each individual user, and try to avoid the orange. And hopefully that's the sort of choices where the machines can do a good job without major risks. But of course you do need more editorial resources to run a system like this.
We're also likely to see success where the computers are used to present options to editors, who can then decide whether they are appropriate or not. "Flags of countries that are red" is the sort of fuzzy question that can the computer can answer quickly, and the editor can then easily spot which flags might be appropriate for their web page about European democracy. They're also quickly able to spot which are not relevant, and which have the potential to cause offence. The computer can save editors time here by collating relevant data, but leave the really important decision of "which image will be best for my users" to the human brain.
The alternative is making the computers even cleverer. And that can't possibly go badly, can it? 😉
Don't get me wrong though – I'm not trying to say "don't use machine learning" – just be aware of the risks and challenges it can pose and make sure you think them through and test with live data before deploying new systems publicly.
↑ Back to topExpired links:
** Some links in this page have expired. The originals are listed here, but they may no longer point to working pages or the correct content:

