
Jeremy Davis
Sitecore, C# and web development
I've spent a bit of time looking at how Regular expressions are changing in the upcoming .Net 7 release. While they do have a bit of a reputation for making people's lives worse (so much there's a well known programmer joke about it) they do have a place in your developer toolbox. So what caught my eye in the new features, and how does code get better with this new version?
 url copied!
url copied!
The need to parse text is pretty common in IT problems, but there's a specific issue I was looking at. I have a long-term personal project to build a "mud" game engine in C#. A core part of any text-based adventure game is parsing user input. And the first step is to split the user's input up into tokens. The game needs to do it every time any player issues a command - so it's a bit of code that can be pretty important for overall performance.
At its simplest, the parser in my game engine takes the string and:
So
give sword to knight
is broken into the tokens
give,
sword,
to
and
knight. And
give sword to "green knight".
would be broken into
give,
sword,
to
and
green knight. Fairly simple - though the following phases where the code works out the meaning of the text is a bit more complicated. (Perhaps a topic for a future post?)
A lot of my coding follows the "make it work, then worry about making it pretty" principle so the current implementation of this parsing is based on simple regular expressions. And tbh, I'd never got to the "make it pretty" phase for this bit of code. The core of the work is the Regex
".*?"|\w*
- that translates roughly as "match any string surrounded in quotes, or match any string of word characters". That generates a
Match
for each token in the user input and those can get stored away for the game engine to use. Stripping out some stuff that's not relevant to this experiment, the core code is roughly this:
public class RegexStringTokeniser
{
private static string quotes = "\"";
private static Regex parser = new Regex("\".*?\"|\\w*", RegexOptions.Singleline | RegexOptions.Compiled);
private List<string> tokens = new List<string>();
public int Count
{
get { return tokens.Count; }
}
public IEnumerable<string> Tokens
{
get
{
foreach (string token in tokens)
{
yield return token;
}
}
}
public RegexStringTokeniser(string input, bool removeQuotes = true)
{
ArgumentNullException.ThrowIfNull(input, nameof(input));
Match m = parser.Match(input);
while (m.Success)
{
if (m.Length > 0)
{
if (removeQuotes)
tokens.Add(m.Value.Replace(quotes, ""));
else
tokens.Add(m.Value);
}
m = m.NextMatch();
}
}
}
Pretty simple - and it works. The only real concession to performance I'd made was to make the regular expression a
static
field and mark it as
RegexOptions.Compiled
to get the performance boost of not having to parse the expression every time.
Measuring that with the excellent BenchmarkDotNet, when it parses a set of test data we get this as a baseline measurement:
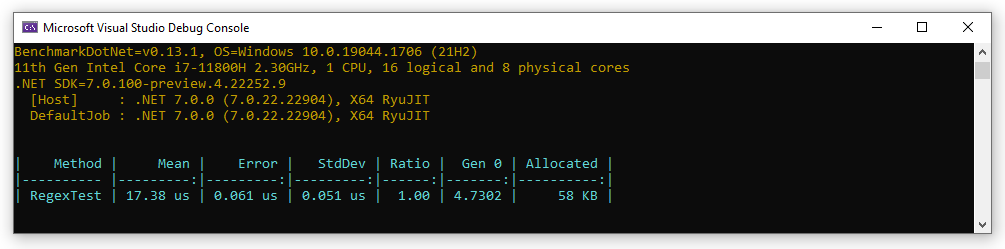
url copied!
Well they're the two things you're fighting with every bit of code you write: CPU usage (execution time) and Allocations (how much memory gets used).
Using a compiled
Regex
reduces the CPU overhead a bit, and up until now that was all I'd really considered. But looking at the code it's fairly obvious that this has some memory effects - It's allocating 58Kb for the 12 tests. Each expression
Match
is a class - a heap allocated object. So every time the matching process runs it's creating and then discarding objects that the GC has to track. And internally, matches are creating strings which get copied about.
So there are opportunities to improve here.
url copied!
The most efficient way of addressing this code is to get rid of the need for regular expressions at all. If we accept the loss of flexibility that comes from hard-coding the matching algorithm, the code can step through the input directly. There's another interesting new .Net feature that can help here:
ReadOnlySpan<T>. (Thought this one is already released, so you can use it now) It's a way of handling "slicing" of arrays of data, and minimising the memory allocations involved. They're not as easy to use as strings, because they're stack-based data they can't be stored in fields or collections. But it's not too difficult to work around that limitiation in order to get the benefits here.
The code above can get rewritten in this style. It's a bit longer and more complex, but the results are interesting:
public class SpanStringTokeniser
{
private List<string> tokens = new List<string>();
public int Count
{
get { return tokens.Count; }
}
public IEnumerable<string> Tokens
{
get
{
foreach (string token in tokens)
{
yield return token;
}
}
}
public SpanStringTokeniser(ReadOnlySpan<char> input, bool removeQuotes=true)
{
int start = 0;
int len = 0;
bool inQuote = false;
do
{
if (!inQuote && input[start + len] == '"')
{
inQuote = true;
len = 0;
if (removeQuotes)
{
start += 1;
}
else
{
len += 1;
}
}
else if (inQuote && input[start + len] == '"')
{
inQuote = false;
if(!removeQuotes)
{
len += 1;
}
tokens.Add(input.Slice(start, len).ToString());
start += len;
if (removeQuotes)
{
start += 1;
}
start += SkipPunctuation(input, start);
len = 0;
}
else if (!inQuote && (char.IsPunctuation(input[start + len]) || char.IsWhiteSpace(input[start + len])) )
{
if (len > 0)
{
tokens.Add(input.Slice(start, len).ToString());
}
start += len + SkipPunctuation(input, start);
len = 0;
}
else
{
len += 1;
}
}
while (start + len < input.Length);
if (start <= input.Length-1)
{
tokens.Add(input.Slice(start).ToString());
}
}
private int SkipPunctuation(ReadOnlySpan<char> input, int pos)
{
int delta = 0;
while( (pos + delta < input.Length) && (char.IsWhiteSpace(input[pos + delta]) || char.IsPunctuation(input[pos + delta])) && input[pos + delta] != '"')
{
delta += 1;
}
return delta;
}
}
(I'm pretty sure this isn't the simplest re-write I could do - it's just a first pass for comparisons. All those nested if/else clauses could be improved for a start...)
Re-doing the measurments to compare this implementation to the original
Regex
gives a nice improvement. It's a quarter of the CPU time, and reduces the memory allocations down to 7Kb:
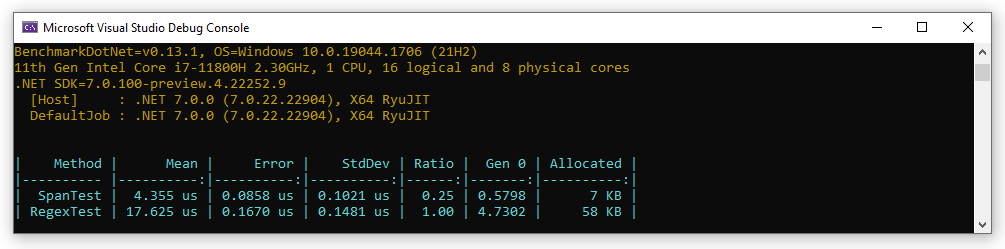
But it's certainly less easy to read...
url copied!
The latest updates in Preview 4 of .Net 7
add a load of change to Regular Expressions. There's a lot of interesting technical detail in that post, but the key things from my perspective are the ability to generate the "compiled"
Regex
at compilation time, and the ability to use ValueTypes to return data about matches.
Converting the original class to this model involves three main changes.
First up, instead of declaring the
Regex
directly the code can now declare a
partial static
property and use the
[RegexGenerator]
attribute to specify what expression needs to be generated. That allows the C# compiler to parse the expression we want generated, and then construct the C# code for it and put it into the compiler-generated file for this partial class.
That change gives two interesting benefits. Firstly it means 100% of the work to turn the regular expression into .Net code happens at compile time, so there's no startup-time penalty for the "compiled" expression that the original code used. And the second is that a side-effect of that is you can now step the debugger into this compiled code, which could be really useful if you need to understand the behaviour of your expression:
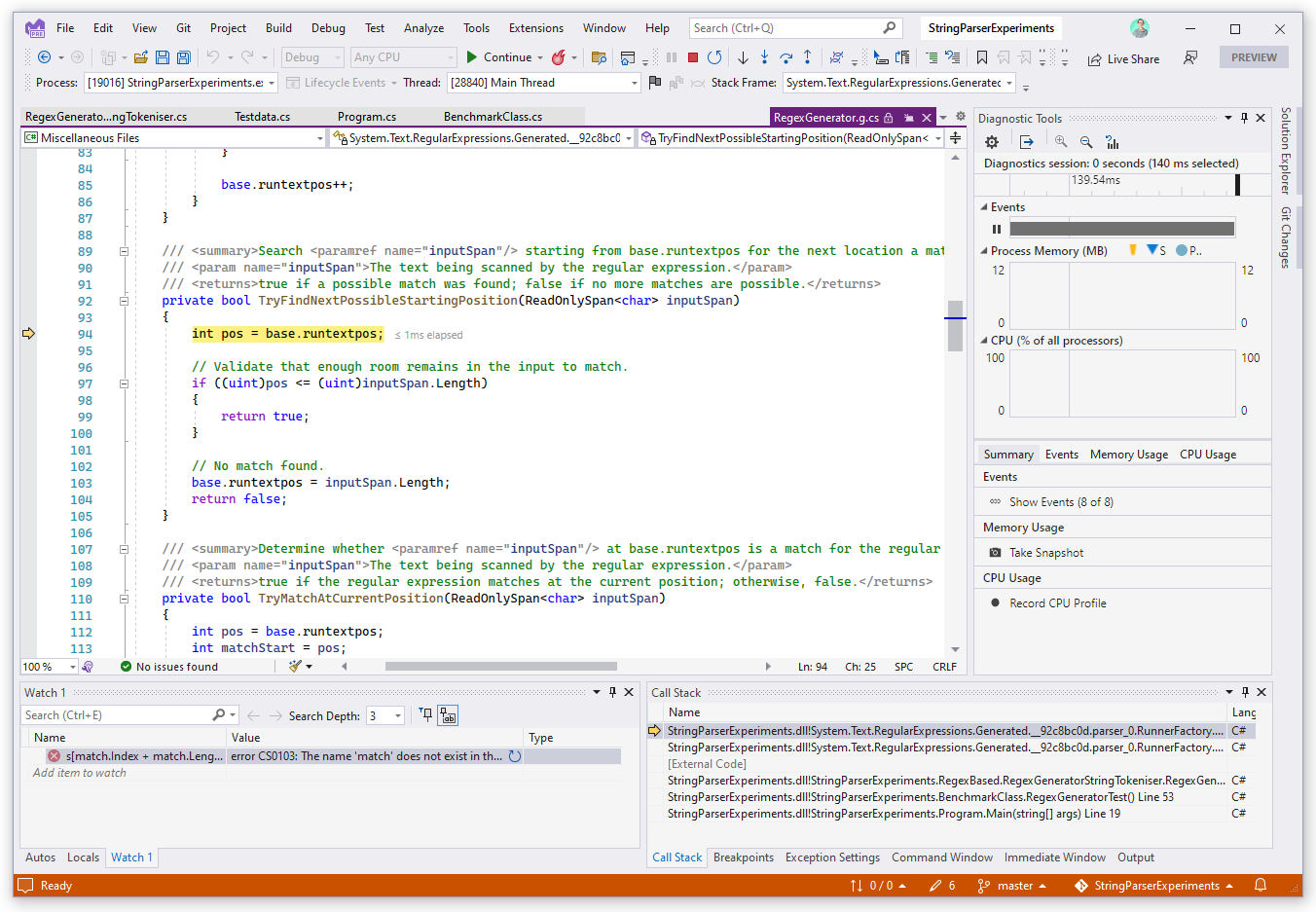
Secondly, to support that change the overall class needs to be declared
partial
too.
And then thirdly, these new
Regex
classes have a new
EnumerateMatches()
method which returns a set of
ValueMatch
data - stack allocated value types so the GC does not have to get involved.
public partial class RegexGeneratorStringTokeniser
{
private static string quotes = "\"";
[RegexGenerator("\".*?\"|\\w*", RegexOptions.Singleline)]
private static partial Regex parser();
private List<string> tokens = new List<string>();
public int Count
{
get { return tokens.Count; }
}
public IEnumerable<string> Tokens
{
get
{
foreach (string token in tokens)
{
yield return token;
}
}
}
public RegexGeneratorStringTokeniser(ReadOnlySpan<char> s, bool removeQuotes = true)
{
if (s == null)
{
throw new ArgumentNullException(nameof(s));
}
foreach (ValueMatch match in parser().EnumerateMatches(s))
{
if(match.Length == 0)
{
continue;
}
if(removeQuotes && s[match.Index] == '"' && s[match.Index + match.Length - 1] == '"')
{
tokens.Add(s.Slice(match.Index + 1, match.Length - 2).ToString());
}
else
{
tokens.Add(s.Slice(match.Index, match.Length).ToString());
}
}
}
}
The code-style police in my head don't really like the use of
parser().EnumerateMatches(s)
there - it would be nicer if
parser
was a property getter not a method. But
partial property getters aren't a thing in C# yet. So I'll just have to put up with that for now...
That code can also take in a
ReadOnlySpan<char>
as its input, as the new
Regex
methods can operate on spans. The
ValueMatch
data gives the starting position and length of each match found. That data can be used to slice the input span to generate the set of result strings.
Re-measuring with this version gives more interesting info:
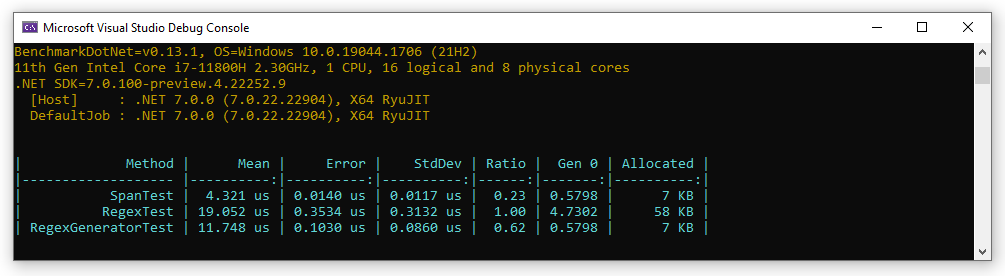
This approach gives some of the performance improvement compared to hand-written code, but it maintains the same improved memory performance as that code.
url copied!
This has been an interesting experiment. It shows that hand-crafting parsing code for your specific scenarios is still likely the fastest approach to whatever you're doing. But if this preview code from Microsoft makes it into the final .Net 7 release, regular expressions can be significantly better than they were before. Which makes it more likely that keeping the flexibility they provide is worthwhile.
↑ Back to top
