
Jeremy Davis
Sitecore, C# and web development
I spend most of my working life building website code at work, and sometimes I get involved in performance work with that sort of system. In fact I've written and presented on that topic for Sitecore in the past. But some code I've been working on in my own time needs much more focus on code performance than that - the maths-heavy code for ray tracing. I've been looking at some optimisiations for that recently. And one thing that this has reinforced for me is how "easy to write" code can have some performance challenges...
 url copied!
url copied!
A while back I bought a book called The Ray Tracer Challenge which describes building a renderer via unit tests. I worked through that book, and built up a codebase in C#, and then added some features of my own for animation and handling the resulting images. And it works pretty well. I've been able to render some interesting images that use reflection, refraction, textures, Constructive Solid Geometry, normal maps and the like:
As I worked through the book I wrote code to be readable and to work, rather than worrying about speed specifically. And since there's a lot of calculation and iteration involved in these images, it can take quite a while to generate each one. The image above calculated 693,326,009 light rays in total and it took nearly half an hour to render the 50 frames in that animation on my Core i7 2.30GHz laptop.
So I started thinking about how I might be able to make it faster and I had two ideas. One was whether I might be able to use the vectorisation support of .Net 9 to do some of the maths faster, and the other was that I might be able to remove some of the overheads in the code that were wasting time. The first one seems like a tricky problem because I think it would involve some fairly significant refactoring of how the current code works. So I decided to focus on the second for a while, and fired up my old friend the Visual Studio profiler...
url copied!
Imagine a camera. Images are made by the light rays that came from The Sun bouncing off the surface of objects and being focused through a lens and onto an image sensor. That sensor (be it chemical film in an old camera, or silicon in a modern digital camera) then gives us our picture.
But in a computer it works kind of the opposite way.
There's a model of "the world" that needs to be drawn, which includes a model of the camera displaying it. That camera's sensor is the output image. And the code does the maths to cast rays of light through the pixels of the sensor into the world in order to work out what colour each pixel should be.
The maths looks at how the light ray that came from the camera would bounce through the scene and if it would eventually end up at a source of light. The way it bounces, what it hits and what the light is determines the final colours.
But it's a lot of calculations. When you start looking at reflections and refractions, or you need to anti-alias edges, lots more rays get cast. And each one involves calculations.
Hence the giant number of rays being processed for the image above. And so it follows that anything I can do to make each ray cause less processing will end up a good thing...
url copied!
When I wrote the code I used a collection of the shortcuts that C# devs often use - and one of those is Linq.
The code models the concept of an
Intersection
- a solution to some equations which specifies the point in space where a ray of light has touched the surface of an object in the scene. At the most basic level the ray stops at that point and there's work to calculate the colour that the point has. But in more complex cases the ray may reflect or refract towards other surfaces and light sources, and the underlying maths for intersecting a ray with the world will find all the intersections that could occur - assuming the ray passed through things. Hence you may get back multiple
Intersection
objects back from the maths.
As a side-effect of that, the code ends up having to sort
Intersetction
objects by their distance from the camera in a few places, in order to find the first place where the ray hits something in space, no matter what order the objects in the scene got processed. This was one of the places where I'd written Linq code for readability. So I had a few places in the source where after some calculuation to find all the possible
Intersection
data, there was something like:
return intersections
.Where(i => i.T >= 0)
.OrderBy(i => i.T)
.FirstOrDefault();
(T
here is the "time" in the maths - basically how far away is the intersection from the camera)
But when I render a small test scene, this turns out to be more expensive an operation than you might initially think. To measure it I've switched the solution to run in release mode, and picked "Debug / Performance Profiler" from VS' main menu. You then need to pick what sort of measurement to take:
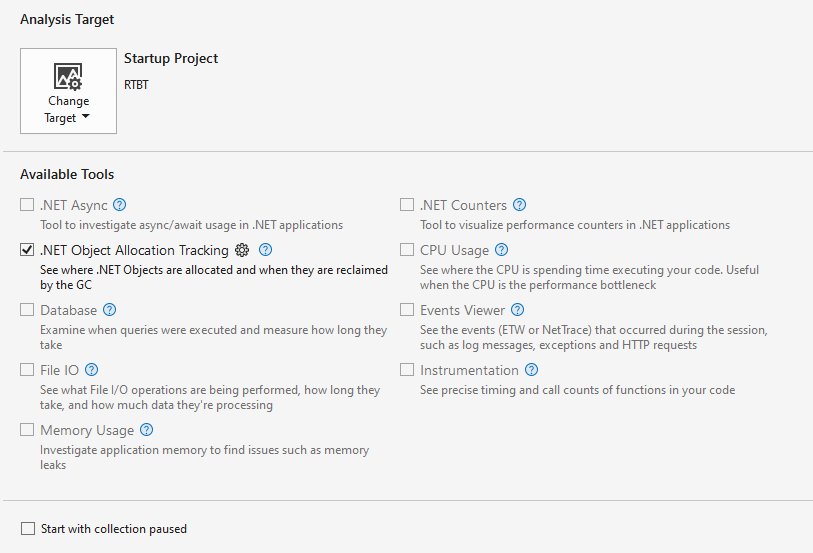
".Net Object Allocation Tracking" is the right one here. Plus I've made sure that the "Analysis Target" is the right project in my solution. (Later, when taking further measurements you can pick "Debug / Relaunch Performance Profiler" to take another measurement with the same settings)
That will run the code to completion, do a bit of thinking, and then present a bunch of data:
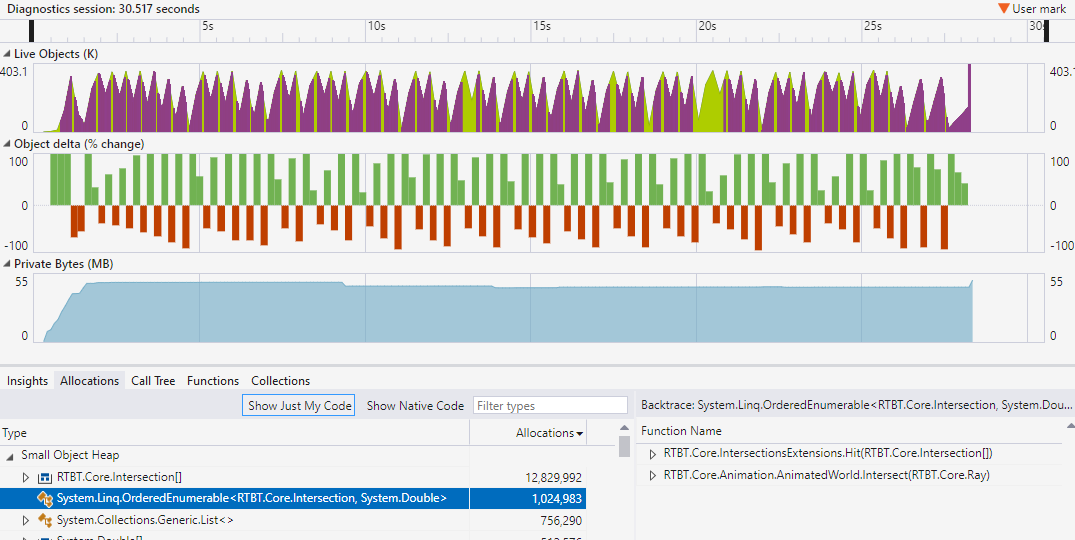
The graph at the top is showing that it took about 28s to render this scene. The easiest to understand data here is shown by selecting "Allocations" in the tabs of the bottom pane, and looking at what has the highest numbers in that list. And here you can see that
System.OrderedEnumerable<Intersection,double>
gets created more than 1M times for this scene. That type is what gets created when Linq sorts a collection.
So that data is telling me that replacing those Linq operations with something that doesn't allocate could make a significant difference.
I started by factoring out that fragment of code as an extension method, and then rewrote the contents of that method so that it scans the existing collection to find the relevant one to return, rather than using Linq:
public static class IntersectionsExtensions
{
public static Intersection Hit(this Intersection[] intersections)
{
int target = -1;
double max = double.MaxValue;
for (int i = 0; i < intersections.Length; i++)
{
if (intersections[i].T < 0)
{
continue;
}
if (intersections[i].T < max)
{
target = i;
max = intersections[i].T;
}
}
if (target == -1)
{
return default;
}
return intersections[target];
}
}
It's longer, and harder to read - but nothing in that method causes any
new
operations... It's looping through each element in the incoming collection, and if it's valid to process, it's checking if this is smaller than the current smallets item found. If so, it keeps that
T
value and the index of the element. And at the end it returns either
default
(if nothing was valid to return) or it returns the relevant item.
Making that change takes the data graph length down to ~20 seconds, and entirely removes those 1M+ allocations.
A good first step.
url copied!
The next thing I noticed was that the single most allocated object type was
Intersection[]
itself. That's not surprising - every ray cast will generate one of these, and each pixel can cast multiple rays. So it seems difficult to avoid creating a lot of this collection:
![The list of allocated types from the profiler dialog - expanded to show all the types of Intersection[] being allocated. Including 10M instances of Intersection[0]](/img/2024/11-ArraysBefore.png)
But it's interesting to note here that the single biggest allocation of these arrays is of
Intersection[0]
- meaning that a lot of rays hit nothing in this scene. And while the rays that do hit seem hard to optimise, the situations where it misses can be sorted farily easily. I realised that the existing code had a lot of sections that looked like a bit like this code which decides if a ray has hit a sphere or not:
protected override Intersection[] LocalIntersect(Ray localRay)
{
var str = localRay.Origin.ToVector();
var a = localRay.Direction.Dot(localRay.Direction);
var b = 2f * localRay.Direction.Dot(str);
var c = str.Dot(str) - 1f;
var disc = (b * b) - 4f * a * c;
if (disc < 0)
{
return new Intersection[0];
}
var sqrt = disc == 0 ? 0 : Math.Sqrt(disc);
var t1 = (-b - sqrt) / (2f * a);
var t2 = (-b + sqrt) / (2f * a);
if (double.IsNaN(t1) || double.IsNaN(t2))
{
return new Intersection[0];
}
return new Intersection[] { new Intersection(t1, this), new Intersection(t2, this) };
}
Note how there are two places there that use
new Intersection[0]
to return a "miss". But being more sensible about this, there is a better way to approach this situation. C# has
Array.Empty<Intersection>()
specifically for this situation. It will share the same instance of this empty array across all references to it - which in this case can get rid of a load more allocations.
While digging through this code I also spotted another array-creation mistake. The code does anti-aliasing for each pixel by firing off multiple rays. For each pixel it goes through the middle, and also a bit up-left, up-right, down-left and down-right for the same pixel. That lets it average out the colour in the surrounding area and make the edges softer. But I realised that this code included
new[]{ (+1, +1), (+1, -1), (-1, +1), (-1, -1) }
in the loop which does this ray casting. Not a great idea - that array of
Tuples
is being recreated for every ray cast. Much better to change that to a field declaration, so it's only ever done once:
private static (int, int)[] _deltas = { (+1, +1), (+1, -1), (-1, +1), (-1, -1) };
So with those two changes implemented across the code, another test showed further improvement. That got rid of 10M empty arrays allocations in the test scene:
![Comparing the before and after of the list of allocated types, showing the Intersection[] objects. Before there are millions of Intersection[0] being allocated. After there are none.](/img/2024/11-ArraysAfter.png)
And that has a big impact on the overall performance. The render speed for the same model dropped to ~5s - a massive 15s less than the prevous run. And that gives an idea of how much effect all that unnecessary garbage collection has on a tight inner maths loop.
I also spotted another challenge with collections. There were a number of places where the code had to do some more complex filtering of the
Intersection
data generated by a ray. An example here is with the maths for cylinders. It needs to manage intersections for both the cylindrical body and for the end-caps. So there were a few places which had code that allocated
List<Intersection>
collections so it can add and remove the relevant intersection data. For example:
var intersections = new List<Intersection>();
... snip ...
var y0 = localRay.Origin.Y + t0 * localRay.Direction.Y;
if (this.Minimum.Value < y0 && y0 < this.Maximum.Value)
{
intersections.Add(new Intersection(t0, this));
}
var y1 = localRay.Origin.Y + t1 * localRay.Direction.Y;
if (this.Minimum.Value < y1 && y1 < this.Maximum.Value)
{
intersections.Add(new Intersection(t1, this));
}
IntersectCaps(localRay, intersections);
return intersections.ToArray();
So this is allocating a lot of objects too - every time a cylinder (or other shape type using the same patterns) is tested, it's allocating a collection. But it's also a trickier one to optimise. The rendering code uses a
Parallel.For()
loop to make sure rays get cast by all your CPU cores at once. So "just make this collection a field" isn't good enough here. One copy of the shape object (because there is only one copy of the scene model in memory) is used by many threads in parallel during rendering.
But .Net does have a helpful object for this scenario. You can declare a special wrapper around your type to mark it as Thread Local. That means any thread which runs this code will have a separate copy of the data, preventing the parallel threads from interfering with each other. So the collection declaration above can change to:
private ThreadLocal<List<Intersection>> _intersection = new ThreadLocal<List<Intersection>>();
And then the original code can change to:
if (_intersection.Value == null)
{
_intersection.Value = new List<Intersection>();
}
else
{
_intersection.Value.Clear();
}
... snip ...
var y0 = localRay.Origin.Y + t0 * localRay.Direction.Y;
if (this.Minimum.Value < y0 && y0 < this.Maximum.Value)
{
_intersection.Value.Add(new Intersection(t0, this));
}
var y1 = localRay.Origin.Y + t1 * localRay.Direction.Y;
if (this.Minimum.Value < y1 && y1 < this.Maximum.Value)
{
_intersection.Value.Add(new Intersection(t1, this));
}
IntersectCaps(localRay, _intersection.Value);
return _intersection.Value.ToArray();
So this change to the code makes sure that the collection exists in its thread-local space, and if it already did clears the data. And that now allocates once per thread and per instance of the shape, instead of per ray cast.
That knocked about another second off the render time, and got rid of 300k allocations.
url copied!
Having made all those changes, I tried adjusting the test scene to work the code harder - one which included both a multi-frame animation and some more complex shapes. And re-running the profiler against this pointed out a new place to consider optimising:
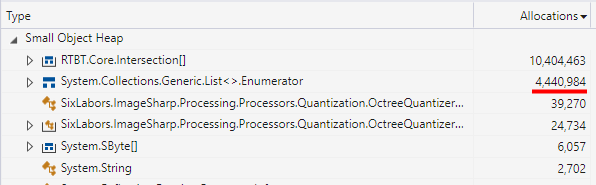
The code included a collection of
foreach()
loops over collections of data. Probably not something you'd worry about normally. But here the measurement shows that those loops cause an
Enumerator
to be created and destroyed each time. And that's ~4M more allocations that can be removed from this test render.
So in a few places I changed from using:
foreach (var geometry in Geometry)
{
var i = geometry.Intersects(ray);
if (i.Length > 0)
{
_intersections.Value.AddRange(i);
}
}
to using a
for()
loop and manually extracting the correct element from the collections:
for(int idx=0; idx<Geometry.Count; idx++)
{
var geometry = Geometry[idx];
var i = geometry.Intersects(ray);
if (i.Length > 0)
{
_intersections.Value.AddRange(i);
}
}
Those changes knocked 1/5th off the render time for this scene, and removed those 4M allocations entirely.
url copied!
None of those were particularly tricky changes - but they had a fairly profound impact on the performance of the overall code.
And while this sort of improvement is most beneficial for the hard-working code here, these are all things that will make a difference in any code that needs avoid memory churn in order to go faster.
So if you need your code to cope with higher loads you might want to consider these issues too...
↑ Back to top
