
Jeremy Davis
Sitecore, C# and web development
A lot of projects I've worked on over the years have had requirements about consuming content feed data over the internet. Whether they're Sitecore projects or not, "we need to display the contents of an RSS Feed" is a fairly common requirement. It should be nice and simple. There are standards and schemas for feed formats like RSS and Atom, so the data should be predictable and easy to handle...
Unfortunately, back in the real world, this rarely seems to be the case. I still regularly come across feeds which don't match the schema, or in extreme cases feeds that aren't even well formed. Sadly some people still seem to think that string concatenation is the way to build XML...
So what are your choices for handling feed data, and how can you try and get around bad-data challenges?

 url copied!
url copied!
For both RSS and Atom feeds, the .Net Framework includes the
System.ServiceModel.Syndication
namespace. It's pretty simple to use:
using (var xml = XmlReader.Create("http://www.indiegames.com/blog/atom.xml"))
{
var feed = SyndicationFeed.Load(xml);
foreach (var item in feed.Items)
{
Console.WriteLine(item.Title.Text);
}
}
Also for both RSS and Atom feeds, the Argotic Framework can be used. This project supports more feed variants than the native .Net library, and it's equally simple to load a basic feed. However note that the class you construct to parse the feed has to be of the correct type. There isn't an obvious base type shared between RSS and Atom feed data that lets you treat an unknown feed in a polymorphic way. You can code around this, but it is an extra complexity.
using (var xml = XmlReader.Create("http://www.indiegames.com/blog/atom.xml"))
{
var feed = new AtomFeed();
feed.Load(xml);
foreach (var item in feed.Entries)
{
Console.WriteLine(item.Title.Content);
}
}
For only RSS feeds, the RSS Toolkit is also available. I've not tied this one myself, however.
None of these libraries are particularly recent, but given that the schemas for the feeds have been stable for some time, this is probably not an issue.
url copied!
var xd = XDocument.Load("http://www.indiegames.com/blog/atom.xml");
XNamespace ns = "http://www.w3.org/2005/Atom";
var titles = xd
.Element(ns + "feed")
.Elements(ns + "entry")
.Elements(ns + "title")
.Select(e => e.Value);
foreach (var title in titles)
{
Console.WriteLine(title);
}
Or you can use an
XmlReader
or even an
XmlDocument
- pick whatever approach best fits your needs and constraints.
But note the need to pay attention to namespaces in code for this. Many feeds have XML which include at least one namespace declaration, and "I didn't use namespaces correctly" is probably the number one reason for XML Parsing code not working the way you think it should.
url copied!
The equivalent code to the examples above needs a little more effort, as the
HtmlDocument
class can't directly load a URL:
using (var wc = new WebClient())
{
var result = wc.DownloadString("http://www.indiegames.com/blog/atom.xml");
var doc = new HtmlDocument();
doc.LoadHtml(result);
var titles = doc.DocumentNode.SelectNodes("/feed/entry/title");
foreach (var title in titles)
{
Console.WriteLine(title.InnerText);
}
}
Now, while this looks great, and works for the title elements example above, if you try to parse out an RSS feed that contains
<link>some url</link>
elements, you'll find that you don't get the results you'd expect:
using (var wc = new WebClient())
{
var result = wc.DownloadString("http://feeds.bbci.co.uk/news/rss.xml?edition=uk");
var doc = new HtmlDocument();
doc.LoadHtml(result);
var links = doc.DocumentNode.SelectNodes("/rss/channel/item/link");
foreach (var link in links)
{
Console.WriteLine(title.InnerText);
}
}
When I run the code above in
LinqPad, I get back the right number of entries in the
links
collection, but their
InnerText
property is always an empty string.
This caused me a bit of head scratching at first, but it turns out that this is part of the Agility Pack's behaviour for parsing elements despite the potential for badly formed markup. The library assumes that the link element is empty, because that is how it's used in HTML. But that assumption is not true for the feed data we're parsing, since RSS uses it with text content.
Luckily the Agility Pack developers saw this issue coming, and gave you a way to change how it treats each element it parses. The
HtmlNode
object exposes a static collection called
ElementFlags
which describes what the parser should do with each element it encounters. It has a set of default values, but you're free to modify them:
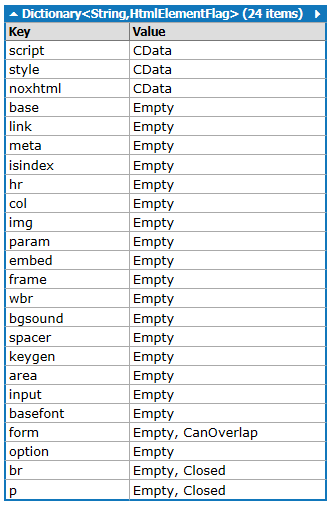
So to change the behaviour for
link
elements we can just remove that entry from the
ElementFlags
collection as below, and the parser will go back to treating it like a normal element containing text:
using (var wc = new WebClient())
{
var result = wc.DownloadString("http://feeds.bbci.co.uk/news/rss.xml?edition=uk");
HtmlNode.ElementsFlags.Remove("link");
var doc = new HtmlDocument();
doc.LoadHtml(result);
var links = doc.DocumentNode.SelectNodes("/rss/channel/item/link");
foreach (var link in links)
{
Console.WriteLine(link.InnerText);
}
}
You may find other elements you need to adjust the behaviour for here. I've found that if you are parsing a feed which fails to close elements which should be closed, adding an explicit "this element should be closed" flag here can help parse the dodgy data. For example, if your feed has trouble with the
title
element, you can add:
HtmlNode.ElementsFlags.Add("title", HtmlElementFlag.Closed);
It can't magically fix the data for you – but it won't throw, and will attempt to deal with the problem for you in a sensible way. What I've found is that if you try to parse something like this:
<?xml version="1.0" encoding="UTF-8"?>
<rss>
<channel>
<title>Test data</title>
<item>
<title>Article one</title>
<link>http://www.test.com/articles/1</link>
</item>
<item>
<title>Article two
<link>http://www.test.com/articles/2</link>
</item>
<item>
<title>Article three</title>
<link>http://www.test.com/articles/3</link>
</item>
</channel>
</rss>
then you'll end up with a result set with one messed up entry, but the rest of the set of titles will be right:
Article one Article twohttp://www.test.com/articles/1 Article three
The text for the title and link get concatenated in the broken
<item/>, and the link text will be empty in this case.
It's not perfect – but in the scenarios I've been working with this result is better than an exception that leads to no feed data at all. And you can always have simple validation rules like "if parsing an entry returns no link, ignore it" to help weed out the entries that get messed up by badly structured XML.
So there you have it – some ideas for your toolbox...
↑ Back to top
