
Jeremy Davis
Sitecore, C# and web development
The one thing that is true of every aspect of IT is that it is always changing. And that change means that things you were confident of in the past may no longer hold true.
I was reminded of this while sitting in the pub with some developers recently, talking about querying for items by path in Sitecore. The debate about the best way to do this raged, but a common thread of the debate was that it is often said that the fastest way to find a set of items you needed is via a ContentSearch index. That assumptions has its roots in the time when most sites were using Lucene to run queries, and for queries with more complex matching rules. But does that hold true here?
 url copied!
url copied!
Measurement.
When you're considering anything to do with performance, I find the best thing to do is run code and measure what actually happens to the system. So to check this assumption, I tried a simple three-way comparison to look at the "time per item" to resolve some queries against the Sitecore Item API, the ContentSearch API against Lucene and ContentSearch against Coveo. (Solr would be good to test too, but I didn't have a machine to hand with that installed)
Based on the content available on the VM I was looking at, I tried three queries inspired by the code that the pub conversation was discussing – returning one item, returning about 13 items and returning about 800 items. The quick bit of code I hacked up to test the Item API was:
private int SingleQueryViaApi()
{
var item = Sitecore.Context.Database.GetItem("{90D7F1B9-78A3-47DE-9A42-F2E3593E5557}");
return 1;
}
private int SmallNumberQueryViaApi()
{
return apiQuery("/sitecore/content/home/folder/somepage");
}
private int LargeNumberQueryViaApi()
{
return apiQuery("/sitecore/content");
}
private int apiQuery(string root)
{
var items = Sitecore.Context.Database.SelectItems("fast:" + root + "//*");
return items.Count();
}
And I tried a similar thing against the two ContentSearch providers with some slightly more complex code:
private int SingleQueryViaCoveoSearch()
{
return singleItemQuery("Coveo_master_index");
}
private int SmallNumberQueryViaCoveoSearch()
{
return searchQuery("/sitecore/content/home/folder/somepage", "Coveo_master_index");
}
private int LargeNumberQueryViaCoveoSearch()
{
return searchQuery("/sitecore/content", "Coveo_master_index");
}
private int SingleQueryViaLuceneSearch()
{
return singleItemQuery("sitecore_master_index");
}
private int SmallNumberQueryViaLuceneSearch()
{
return searchQuery("/sitecore/content/home/folder/somepage", "sitecore_master_index");
}
private int LargeNumberQueryViaLuceneSearch()
{
return searchQuery("/sitecore/content", "sitecore_master_index");
}
private int singleItemQuery(string indexName)
{
var id = new Sitecore.Data.ID("{90D7F1B9-78A3-47DE-9A42-F2E3593E5557}");
var index = ContentSearchManager.GetIndex(indexName);
var predicate = PredicateBuilder.True<SearchResultItem>();
predicate = predicate.And(f => f.ItemId == id);
predicate = predicate.And(f => f.Language == "en");
return runQuery(index, predicate);
}
private int searchQuery(string rootPath, string indexName)
{
var root = Sitecore.Context.Database.GetItem(rootPath);
var index = ContentSearchManager.GetIndex(indexName);
var predicate = PredicateBuilder.True<SearchResultItem>();
predicate = predicate.And(f => f.Language == "en");
return runQuery(index, predicate);
}
private int runQuery(ISearchIndex index, System.Linq.Expressions.Expression<Func<SearchResultItem, bool>> predicate)
{
using (IProviderSearchContext context = index.CreateSearchContext())
{
var query = context
.GetQueryable<SearchResultItem>()
.Filter(predicate);
var total = query.GetResults();
return total.TotalSearchResults;
}
}
To get some measurements of the time they required the calls above can be wrapped up in a method that measures execution time for a certain number of iterations and returns an average time as well as the number of items returned by the query. Something like:
private Tuple<TimeSpan,int> Average(Func<int> action, int iterations)
{
int count = 0;
long ticksSum = 0;
Stopwatch sw = new Stopwatch();
for (int i = 0; i < iterations; i++)
{
sw.Reset();
sw.Start();
count = action();
sw.Stop();
ticksSum += sw.ElapsedTicks;
}
return new Tuple<TimeSpan, int>(new TimeSpan(ticksSum / iterations), count);
}
And from that data, the test can display the total and per-item times for each of these queries.
url copied!
| Query mechanism | 1 item | 13 items | 835 items |
|---|---|---|---|
| Item API | 0.0098ms 0.0098ms/Item |
0.5953ms 0.0458ms/Item |
7.9388ms 0.0095ms/Item |
| Coveo | 11.6366ms 11.6366ms/Item |
28.4449ms 2.0318ms/Item |
29.9235ms 0.0352ms/Item |
| Lucene | 1.2582ms 1.2582ms/Item |
1.2192ms 0.0871ms/Item |
2.047ms 0.0024ms/Item |
Or, if you prefer a graph, the item-per-item data looks like this:
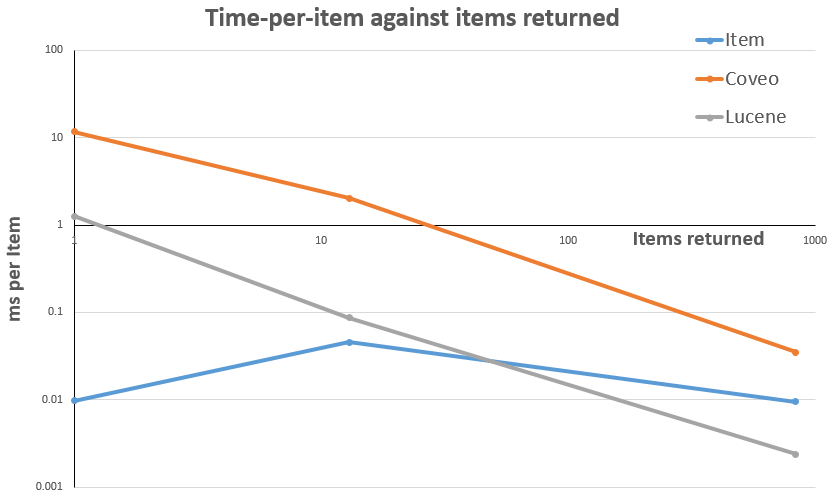
Don't take these numbers too literally though, as the exact figures will be dependent a lot of factors – including the content and the particular performance of the server I ran the code on. It's the trends that are interesting here.
url copied!
For getting a single item, the Item API wins by some distance. That's not particularly surprising though, as the indexing and caching of the underlying content databases are optimised for exactly that scenario, while the search APIs are optimised towards solving more complex queries and doing things like text matching.
What's more interesting (for the debate I was having in the pub) is that for these simple path-based queries, the Item API is also faster when fetching a small collection of items from a content tree. Again "does the query fit into your caches" is probably a key factor here.
But Lucene easily comes out on top when you need to deal with a lot of items. The in-process execution and its optimisations work well in this scenario. And as the complexity of queries increase (especially if they involve text matching), this difference is likely to increase. Shame it's rarely used these days, eh?
Coveo doesn't win on any of these counts – which is most likely due to it's out-of-process execution. In this case the Coveo services were running on the same server, but you can see from the large time difference for the single-item query, there is a relatively large overhead for this remote call. However the difference between the total time for medium and large queries is pretty small in comparison – showing that once the overheads are dealt with, the actual time spent answering the query is small even for larger results sets.
But, outside of all of that detail, there's one key message here: If performance is important to you, rather than making assumptions about how your code will perform, write something that works and then measure it. That gives you a baseline to understand how any changes or alternate solutions measure up.
And that means your decisions can be made on real-world performance, rather than on assumptions you've made in the past...
↑ Back to top
