
Jeremy Davis
Sitecore, C# and web development
Last time out I was looking at applying async/await patterns to some pipeline patterns for C#. After I came up with the initial solution I outlined in that post, there was some more back-and-forth in the discussion thread that prompted all this. And that discussion made me realise there was an interesting side effect of the code I wrote, which might lead to some confusing bugs. So back to the drawing board...
 url copied!
url copied!
public class ExampleAsyncPipeline : AsyncPipeline<Uri, string>
{
public ExampleAsyncPipeline()
{
_pipelineSteps = input => input
.Step(new HttpFetchAsyncStep())
.Step(new ModifyTextAsyncStep())
.Step(new DiskWriteAsyncStep());
}
}
As the steps say: Grab some data, modify the data, and write it to disk somewhere. And we'll add in some debug output. The first step does the fetch. It outputs some debug data on entry, after the
await
returns for the input data, and then just before returning.
public class HttpFetchAsyncStep : IAsyncPipelineStep<Uri, string>
{
private static readonly HttpClient _client = new HttpClient();
public async Task<string> ProcessAsync(Task<Uri> Input)
{
Console.WriteLine("Entering HttpFetchAsyncStep #1");
var uri = await Input;
Console.WriteLine("Have Input HttpFetchAsyncStep #1");
Console.WriteLine("Leaving HttpFetchAsyncStep #1");
return await _client.GetStringAsync(uri);
}
}
The second step just does a simple text replacement to show it did something. And it also outputs debug data at the same points in its execution.
public class ModifyTextAsyncStep : IAsyncPipelineStep<string, string>
{
public async Task<string> ProcessAsync(Task<string> Input)
{
Console.WriteLine("Entering ModifyTextAsyncStep #2");
var txt = await Input;
Console.WriteLine("Have Input ModifyTextAsyncStep #2");
var output = txt.Replace("BBC", "Not the BBC");
Console.WriteLine("Leaving ModifyTextAsyncStep #2");
return output;
}
}
And finally, with the same debug output pattern, the third step works out where the desktop folder is and writes the data it receives to that folder.
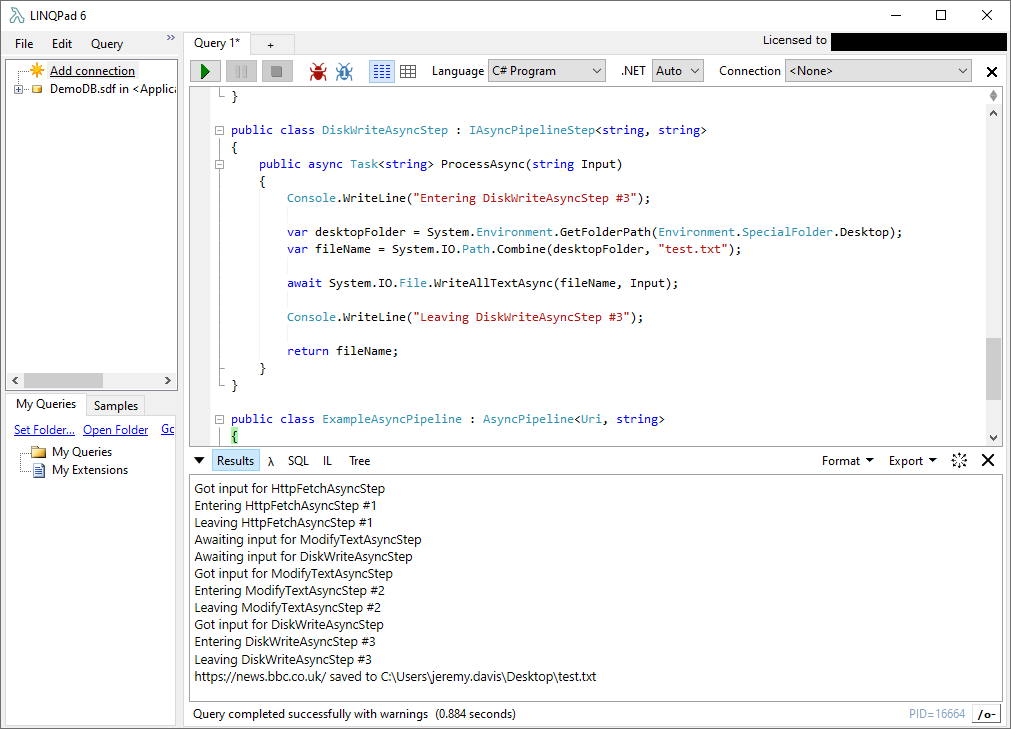
public class DiskWriteAsyncStep : IAsyncPipelineStep<string, string>
{
public async Task<string> ProcessAsync(Task<string> Input)
{
Console.WriteLine("Entering DiskWriteAsyncStep #3");
var data = await Input;
Console.WriteLine("Have Input DiskWriteAsyncStep #3");
var desktopFolder = System.Environment.GetFolderPath(Environment.SpecialFolder.Desktop);
var fileName = System.IO.Path.Combine(desktopFolder, "test.txt");
await System.IO.File.WriteAllTextAsync(fileName, data);
Console.WriteLine("Leaving DiskWriteAsyncStep #3");
return fileName;
}
}
So if we run that pipeline, passing in a valid url, then the debug output looks interesting:
Entering HttpFetchAsyncStep #1 Have Input HttpFetchAsyncStep #1 Leaving HttpFetchAsyncStep #1 Entering ModifyTextAsyncStep #2 Entering DiskWriteAsyncStep #3 Have Input ModifyTextAsyncStep #2 Leaving ModifyTextAsyncStep #2 Have Input DiskWriteAsyncStep #3 Leaving DiskWriteAsyncStep #3
The first step proceeds as we'd expect – entering, getting data, and returning. But then the second step enters, and then immediately the third step enters. Then the second step gets its input and leaves before the third step does the same...
Initially that seems wrong – why would parts of step two and three appear to happen out of order? But I think this is actually a side-effect of how async code works. A statement which awaits a task is going to do one of two things. Either the task is complete and the value is returned immediately, or the task is not complete and the code tries to find something else to do in order to fill its time. In our case, the first step's
await
is of the first case - the input task already has its value, because the source uri was provided at the start of the pipeline. So that just runs through linearly that code without any distractions.
But when we get to step two, its input is the task to read from the remote website. The code enters that step as usual, but the
await
cannot immediately resolve into downloaded html. So the compiler's clever rewriting takes over. This bit of code gets "parked" while it waits for the promise-of-future-data to resolve, and the flow of execution moves on to something else that can be run. In this case, it tries to start the third step, and prints its debug data because that doesn't depend on anything else. But once it gets to awaiting step three's input, the execution has to stall again because that
await
depends on step two's output. So now the flow of execution has nothing else to do but wait for step two's input to resolve, so it can then finish that step, and then finish step three.
And that's what we're seeing in the output above...
url copied!
But after I sat and thought about this a bit harder, I realised that it would be possible to cause some really interesting bugs with this approach. Any code that runs before the
await
in a pipeline step might happen some undefined amount of time before the remainder of the code.
Imagine if the code took a lock on a database table, awaited the input of a really long-running network operation, and then carried on to write something to the database. That code would almost certainly run ok on a developer's computer. But under load in the real world, you could end up with some horrible performance issues where nobody else can do anything to the database table while this bit of code sits and waits for async operations to complete. In broad strokes:
public class CauseAnIssueAsyncStep : IAsyncPipelineStep<string, string>
{
public async Task<string> ProcessAsync(Task<string> Input)
{
TakeOutSomeLocks();
var data = FetchSomeSynchronousData();
var slowThingThatTakesAges = await Input;
var result = FurtherWork(data, slowThingThatTakesAges);
return result;
}
}
And with just the right "wrong code" happening before that initial await I'm pretty sure it would be possible to cause deadlocks, and really mess up your day.
Clearly this code pattern is not great. So how can we resolve this issue?
url copied!
I've tried a couple of attempts at this. My first pass worked on the basis that you could have an abstract base type for pipeline steps which dealt with the awaiting of the inputs. But I didn't want to restrict the pipeline steps to inheriting a base class – that didn't look quite right to me. so I tried a second attempt.
The basic pipleline component interface goes back to having a
TIn
and a
Task<T>
result:
public interface IAsyncPipelineStep<TIn, TOut>
{
Task<TOut> ProcessAsync(TIn Input);
}
And the type for the overall pipeline keeps a
Func<TIn, Task>
for the steps, and exposes the
Task ProcessAsync(TIn Input)
method for executing the complete pipeline:
public abstract class AsyncPipeline<TIn, TOut> : IAsyncPipelineStep<TIn, TOut>
{
public Func<TIn, Task<TOut>> _pipelineSteps { get; protected set; }
public Task<TOut> ProcessAsync(TIn Input)
{
return _pipelineSteps(Input);
}
}
The extension class for composing the steps needs two methods now. One takes a
TIn
input, and runs the step on it directly. And the other takes a
Task
and awaits the result before running the step over this value:
public static class AsyncPipelineStepExtensions
{
public async static Task<TOut> Step<TIn, TOut>(this Task<TIn> Input, IAsyncPipelineStep<TIn, TOut> Step)
{
var input = await Input;
return await Step.ProcessAsync(input);
}
public async static Task<TOut> Step<TIn, TOut>(this TIn Input, IAsyncPipelineStep<TIn, TOut> Step)
{
return await Step.ProcessAsync(Input);
}
}
With all those changes, the three example steps look largely the same. But now theydon't need to
await
their input now, because that bit of boilerplate has been abstracted away:
public class HttpFetchAsyncStep : IAsyncPipelineStep<Uri, string>
{
private static readonly HttpClient _client = new HttpClient();
public async Task<string> ProcessAsync(Uri Input)
{
Console.WriteLine("Entering HttpFetchAsyncStep #1");
Console.WriteLine("Leaving HttpFetchAsyncStep #1");
return await _client.GetStringAsync(Input);
}
}
public class ModifyTextAsyncStep : IAsyncPipelineStep<string, string>
{
public async Task<string> ProcessAsync(string Input)
{
Console.WriteLine("Entering ModifyTextAsyncStep #2");
var output = Input.Replace("BBC", "Not the BBC");
Console.WriteLine("Leaving ModifyTextAsyncStep #2");
return output;
}
}
public class DiskWriteAsyncStep : IAsyncPipelineStep<string, string>
{
public async Task<string> ProcessAsync(string Input)
{
Console.WriteLine("Entering DiskWriteAsyncStep #3");
var desktopFolder = System.Environment.GetFolderPath(Environment.SpecialFolder.Desktop);
var fileName = System.IO.Path.Combine(desktopFolder, "test.txt");
await System.IO.File.WriteAllTextAsync(fileName, Input);
Console.WriteLine("Leaving DiskWriteAsyncStep #3");
return fileName;
}
}
The definition of the overall pipeline doesn't change, despite the changes to the underlying types:
public class ExampleAsyncPipeline : AsyncPipeline<Uri, string>
{
public ExampleAsyncPipeline()
{
_pipelineSteps = input => input
.Step(new HttpFetchAsyncStep())
.Step(new ModifyTextAsyncStep())
.Step(new DiskWriteAsyncStep());
}
}
To my eye, that approach looks better. It's only a small change really, but it's taken away the ability to make a mistake, without changing the core of how it works.
And running it produces the output we'd expect:
As before, this version of the code is available as a gist if you want to play with it.
↑ Back to top
