
Jeremy Davis
Sitecore, C# and web development
I was looking at writing a tool in .Net 7 the other day which would benefit from having an option to load and unload plugin extensions. Reloadable plugins could be a bit tricky in .Net 4, but doable. But that's changed dramatically in more recent framework versions, in some ways that are better and interesting.
 url copied!
url copied!
In the past, if I needed to be able to unload or reload plugin-type code in a .Net application there were two main approaches: You could write the plugins as scripts that were interpreted at runtime, or you could use a separate
AppDomain
to load the code.
Scripting approaches are generally slower, involve learning a second language and require plumbing its runtime into your app. But things like NLua do a lot of the heavy lifting for you. If your plugin changes, you reload the source and next time it is run you get the new code automatically. This tends to have an impact on the GC, as interperting the source can be a bit heavy on allocations. But this approach remains farly simple to get working, even if it's not always easy to make it run fast...
flowchart LR
subgraph A[App]
logic[Logic
of the
App]
script[Script Engine
executes script]
end
files[Script Files
for Plugins]
logic--calls-->script
files--loaded-->script
The pure .Net approach involved writing your plugins as separate DLLs and loading them at runtime. This gave you code which was nearly as fast as without allowing plugins, but once code was loaded you could not easily unload it again. The way around that was to ensure you loaded the external code into a separate
AppDomain. That separation allowed unloading, but forced you to interact with the separated code via remoting - which made the architecture a bit trickier and accounted for the slightly lower performance due to the marshalling of data across that remoting boundary.
flowchart LR
subgraph A[App]
logic[Logic
of the
App]
subgraph D[AppDomain]
proxy[Remoting
Proxy]
object[Plugin
Code]
end
end
files[Plugin
DLLs]
logic--calls-->proxy
proxy--calls-->object
files--loaded-->D
But AppDomains ceased to exist in .Net Core. It seems like this was largely because Microsoft wanted to get rid of the security related features, because they didn't think these worked well. And as a side-effect they had a better idea about how to do the unloading behaviour without that security boundary.
url copied!
The new model revolves around
AssemblyLoadContext
objects. These provide a mechanism for loading assemblies into your process, in a context which can later be unloaded. Since it doesn't have the security boundary there's no need for the remoting so it's simpler to make use of than the older model. At its simplest, your context object just inherits from the framework's base type:
public class MyLoadContext : AssemblyLoadContext
{
}
You can create an instance of this, and use it to load DLLs with the methods it exposes:
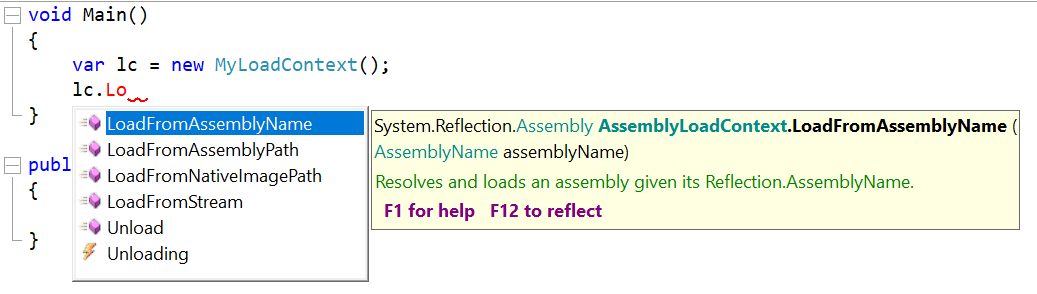
And once you're done, you can call
Unload()
to throw the context out of memory again:
var lc = new MyLoadContext(); // do stuff lc.Unload();
As long as there are no references to any of the code inside your context that remain active, the GC can now tidy up all the memory used by the context - allowing you to reload other things in their place. Note that the object is not
IDisposable
though.
You're also able to have separate contexts to load different versions of the same assembly if you need to. Something like:
var lc1 = new MyLoadContext();
var v1 = lc1.LoadFromAssemblyPath("MyCode.VersionOne.dll");
var lc2 = new MyLoadContext();
var v2 = lc2.LoadFromAssemblyPath("MyCode.VersionOne.dll");
// do stuff
lc2.Unload();
lc1.Unload();
I've not tried it - but this could be a solution to those intractable problems of "because of dependencies, my code needs two different versions of <some library> and I can't fix this with version binding redirects" that pop up every so often.
The "doing stuff" part of this needs a little thought though. Since the code is loaded into your custom context objects, you need to provide ways to interact with that code via your context. For example you might add a
DoStuff()
method to your context which performs the work you need. For example a very simple plugin framework might look like:
public interface IPluginObject
{
void Invoke();
}
public class MyLoadContext : AssemblyLoadContext
{
private IPluginObject _object;
public void Initialise()
{
var assembly = this.LoadFromAssemblyPath("MyCustomCode.dll");
_object = assembly.GetTypes()
.Where(t => t.IsAssignableTo(typeof(IPluginObject)))
.First()
.GetConstructor(Type.EmptyTypes)
.Invoke(Array.Empty<object>()) as IPluginObject;
}
public void DoStuff()
{
_object.Invoke();
}
}
When
Initisalise()
is called, the context loads the required code from a DLL via reflection and takes a reference to the object it creates. So when
DoStuff()
is called it can invoke that object. This pattern has the advantage that you're not passing references to the loaded types outside of the context, so you're guaranteed that the
Unload()
call can free up the space without anything being kept in memory by external references.
But in many situations you can find that the
DoStuff()
behaviour in real-world app looks more like:
public class MyLoadContext : AssemblyLoadContext
{
private IPluginObject _object;
// snip initialisation
public PluginOutputData DoStuff()
{
return _object.Invoke();
}
}
(and looking back to the earlier example of loading multiple versions DLLs, there's a related issue where your context is returning loaded Assemblies directly into the calling program)
Here, if your equivalent of the
PluginOutputData
objects are defined in the DLL that
Initialise()
loads, then you need to take more care around unloading. The DLL can't be removed from memory while there are live references to any of these
PluginOutputData
objects from the GC's perspective. So a call to
Unload()
will succeed, but the GC will not be able to free the memory. So if you have a situation where code is loaded and unloaded often, this can lead to something which looks like a memory leak. This is probably not much of an issue if the load/unload behaviour is only done once for each run of your app. But if you do unload and load more often it might cause problems over the lifespan of a longer running process.
As noted above, there's no remoting going on here. While your load context is tracking loaded assemblies to allow unloading, it's not partitioning them off into a separate memory space. Hence it does not matter if any of the types involved here are serialisable, and you don't need to do anything complicated with unwrapping of references to objects inside and outside if the load context. So there's much less overhead in the code here, compared to the older model. But that's because of the loss of the security boundary...
url copied!
Life is trickier here. The original
AppDomain
model above is pretty easy when you don't need the boundary, but Microsoft have backed away from implementing any sort of security model here. Which means it's up to you to do it yourself - and that is somewhat trickier.
Having decided that the "Code Access Security" model in the old
AppDomain
model wasn't actually working the way they wanted it to, it's now up to you to manage this security boundary explicitly in your code. And funadmentally that means you need to run untrusted code in a separate process to keep it isolated. In effect you have to sort out the
AppDomain
boundary and the remoting between the isolated bits of code yourself. Something like:
flowchart LR
subgraph P1[Main App Process]
LOGIC[Main App
Logic]
CTX1[Remoting
context]
end
subgraph P2[Low Trust Process]
CTX2[Remoting
context]
CONTEXT[LoadContext
for plugins]
end
PLUGIN[Plugin
DLLs]
LOGIC--Calls-->CTX1
CTX1--Calls-->CTX2
CTX2--Calls-->CONTEXT
PLUGIN--Loaded-->CONTEXT
The structure is very much like the old AppDomain model, but you have to manage all of this yourself now. Including spinning up that separate process with lower security.
url copied!
The particular example I was looking at that started me down this road probably doesn't need to explicitly manage security. It's not loading code from the internet, or anything risky like that. So I'm thinking this new model will be simpler for my scenario. But I think I still need to spend a bit of time wrapping my head around the right way to structure this in my app, since the patterns have changed enough that I think I've still got some learning to do...
↑ Back to top
