
Jeremy Davis
Sitecore, C# and web development
I've written a few times before about trying to smooth out the rougher edges of the process of blogging with some custom tooling. Both the site generator I'm using these days, and the simple editor tool I hacked together to suit my writing process. I realised recently that one of those rough edges that remained in the process was the need to manually commit my writing to source control, so I wondered what it might take to wire that into my editing tool...
 url copied!
url copied!
I have two separate git repos for my blog:
One is in Github, to provide the Github Pages site that I publish to. This repo contains only the output of my static site generator, and I automated the process of updating this early in my migration, with a "build and publish the site" PowerShell script which I can run from the command line.
The second repo is a self-hosted one which holds the source for the blog, the editor and the static site generator. The basic markdown for the pages, the Razor and custom C# code for the theme, and the WPF app that I write most of the posts in. This one doesn't have any automation right now. When I do some writing and am ready to commit the changes I've usually just opened Visual Studio to commit and push.
And that's the thing I was interested in improving. Could I add the Git process to the editing tool, so I didn't have to load VS in order to save changes to my repo?
url copied!
It's three operations:
Maybe there's some other stuff too - my writing is usually just committed direct to the "main" branch, but it's not uncommon for me also to have some live side branches for code changes, or more significate site layout changes that I need to spend more time working on. So potentially the tooling needs to be able to cope with making sure that we're using the right branch.
And with the heavy heart of an experienced developer, there will need to be a way to detect (and maybe handle) error conditions. From the trivial "what happens if the computer is offline, but it's trying to push to a remote" to the less simple but important "the remote is ahead of local, and you won't be able to push".
And those needs got me thinking about possible approaches.
url copied!
My first instinct was a simple but hacky one: Git is a command line tool, so can spawn it using the
System.Diagnostics.Process
class. It's a fair assumption that the git tooling will be available via the system Path, so it's easy to get the current changes:
var psi = new ProcessStartInfo(){
FileName = "git",
Arguments = "status -s -uall",
WorkingDirectory = "\Your\Project\Folder"
};
using var p = Process.Start(psi);
That's setting up the execution of Git, and running the
status -s -uall
command. That will get the current changes with two important settings. Firstly
-s
outputs the simplest status data, avoiding all the cruft that Git will show by default, and secondly
-uall
makes sure it lists any untracked file changes as well as tracked ones, so you can see new files need adding. From the command line, running that gets you something like:
?? SomeFolder/MyFeature/SomeNewFile.cs M SomeFolder/Notes.txt
The
M
indicates a tracked file was modified, and the
??
indicates a new untracked file has been created.
But running that as-is isn't wildly helpful. It'll flash up a console window, show the output and then it'll vanish again - likely too fast to see. We need the output to be available to our calling program though, and we probably don't want to actually show the console window. That involves a few extra lines:
var psi = new ProcessStartInfo(){
FileName = "git",
Arguments = "status -s -uall",
WorkingDirectory = "\Your\Project\Folder",
RedirectStandardOutput = true,
CreateNoWindow = true
};
using var p = Process.Start(psi);
p.WaitForExit();
var outputStream = new System.IO.StreamReader(p.StandardOutput.BaseStream);
var result = outputStream.ReadToEnd();
In the
ProcessStartInfo
declaration, adding the
CreateNoWindow
setting means that Git will get run in the background, rather than popping up a console briefly. And the
RedirectStandardOutput
setting will send whatever Git writes to the console window to a stream that our code can read. Then the call to
WaitForExit()
pauses your program until the spawned instance of Git finishes executing, and then the
StreamReader
allows the data captured for the standard output to be read as a string.
That gets the same text as shown in the console, but now it's sitting in the
result
variable for onward processing.
With that in place, you can also make calls with the arguments set to
add .,
commit -m "<a message>"
and
push
complete the basic process of sending a commit to a remote.
But what this doesn't handle is error conditions. Git is a well behaved console app, so you can capture these fairly easily. You can also use
RedirectStandardError = true
in the setup of
ProcessStartInfo
to send any error text to another stream, and read it out inside the same way that the code above gets the
StandardOutput
stream.
And other things like swapping branches can be handled in a similar manner by using the appropriate Git commands.
But the basic challenge with this approach is the need to parse all the results out of the output or error streams. And that tends to be a bit of a pain, and it's also quite sensitive to whether different versions of Git change the structure of the text they output.
And that made me think about more structured ways of doing this...
url copied!
Would an API do better? It should allow for an easier way of handling results at least. A bit of googling pointed me towards the
libgit2sharp
project. That's a .Net wrapper around the native
libgit2
library.
Adding the Nuget package to a project allows fetching changes fairly simply:
using LibGit2Sharp;
var repoPath = @"<path to your repo>";
using (var repo = new Repository(repoPath))
{
foreach (var item in repo.RetrieveStatus(new LibGit2Sharp.StatusOptions()))
{
if (item.State != FileStatus.Ignored)
{
// do something with the changed item
}
}
}
The
item
here has
a collection of relevant properties
which can be used for display or filtering.
And similarly this library has methods for the add, commit and push commands. So it can clearly achieve the same behaviour as the command line, but without the need to do the parsing of text.
But where this approach becomes more complex is with things like commit. Example code for this might look like:
using LibGit2Sharp;
var repoPath = @"<path to your repo>";
var userName = "Jeremy";
var userEmail = "jeremy@email.net";
var commitMessage = "<your commit message>";
using (var repo = new Repository(repoPath))
{
// do whatever is needed to add the changes
Signature author = new Signature(userName, userEmail, DateTime.Now);
Signature committer = author;
// Commit to the repository
Commit commit = repo.Commit(commitMessage, author, committer);
}
Unlike the command line (which just remembers this stuff), this code needs to know who you're committing as each time you call it. And similarly, attempting to push changes requires knowing credentials for the remote, which Git would have handled for you.
So while this approach gives you data in an easier format to process, it still has some challenges...
url copied!
After some fun hacking, I have a basic experiment that works: A prototype window my the editor looks like this:
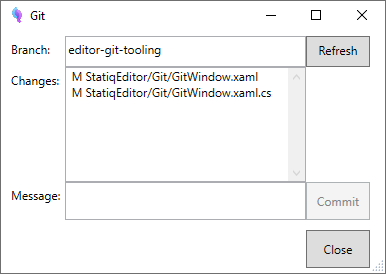
And whilst this definitely needs some revision, I can see if the branch is right (though not change it yet) and can commit/push the changes outstanding. I still need to get to a place where I'm happy with error handling though, as currently it just reports output rather than understanding what happened.
Learning from messing about with this, I'm coming to the conclusion that for me the "right" answer for me is a hybrid of these approaches. I don't want to add the complexity to my app of managing credentials, but for some operations it's easier to parse data from the API. For example, getting the current branch with an API call to
repo.Branches, but committing and pushing is easier via the command line.
So I'm still experimenting with the UI and code I want here. But it's useful to know that you have choices, and I have a feeling the API surface for Git may be useful for other tools too...
↑ Back to top
