
Jeremy Davis
Sitecore, C# and web development
I've wanted to add some logic to this site to display article headings as navigation for a while. And I've also been thinking it would be helpful if you were able to link directly to headings. Pleasingly the Statiq engine makes doing this pretty simple, so here's how my attempt works:
 url copied!
url copied!
Any post can contain headings. This will be level 2 to level 4 headings (since level 1 is used by the layout for the page) and they can be expressed as either markdown or as html elements:
## This is a level two heading in markdown <h3>and this is level three expressed as html</h3>
The code needs to search the post's copy for these patterns, and for each thing it finds it should:
<a/>
element with a
name
attribute so that it can be linked toSo what does that look like in code?
url copied!
Statiq is based on a pipeline-style architecture, so the first step is to add an
IConfigurator
class to add the custom code into the engine:
public class HeadingSummaryConfigurator : IConfigurator<Bootstrapper>
{
public void Configure(Bootstrapper configurable)
{
configurable.ModifyPipeline("Content", p =>
{
p.ProcessModules.Insert(2, new HeadingSummaryModule());
});
}
}
The right pipeline here is the
Content
one, and the custom code needs to happen fairly early in the pipeline - after the document data has been loaded.
That class refers to the
HeadingSummaryModule
class, whose structure is simple:
public class HeadingSummaryModule : ParallelModule
{
protected override async Task<IEnumerable<IDocument>> ExecuteInputAsync(IDocument input, IExecutionContext context)
{
// logic goes here
}
}
url copied!
This code is only interested in blog posts. They can be identified by the facts that they're
.md
files, and that their path includes
/posts/
so the overall
Execute()
method needs a test to check if the current file meets those criteria. so it becomes:
protected override async Task<IEnumerable<IDocument>> ExecuteInputAsync(IDocument input, IExecutionContext context)
{
if (input.Source.Extension == ".md" && input.Source.FullPath.Contains("/posts/"))
{
// this is a blog post
// so rest of logic goes here
}
// if nothing gets processed, just pass the data straight through
return input.Yield();
}
Then the next step is to get the content and find any headings it contains:
var headingSummary = new StringBuilder(); var content = await input.GetContentStringAsync(); var headings = _headings.Matches(content);
The
_headings
field is a regular expression to do the finding:
private static Regex _headings = new Regex("(?<level>\\#{2,4})(\\s*)(?<linkText>.*?)$|<h(?<level>.)>(?<linkText>.*?)</h.>(\\s*)$", RegexOptions.Compiled | RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.ExplicitCapture);
That looks a bit messy, but it's an "or" of two separate tests. The first finds the markdown headings:
(?<level>\\#{2,4})(\\s*)(?<linkText>.*?)$
That matches 2-4 '#' characters as the "level" group, skips any whitespace and then matches the rest of the line as the "linkText" group.
And then second finds the HTML headings:
<h(?<level>.)>(?<linkText>.*?)</h.>(\\s*)$
That matches the start of an
h
element, with its level number in the "level" group. It matches the content of the element into the "linkText" group, and then it matches the closing tag and any whitespace to the end of the line.
That does make some assumptions about how headings have been used here (e.g. that heading elements have not been wrapped in other elements, or that don't have any attributes set) but these assumptions work for the data I have.
So once that match completes the code can iterate over the results (assuming there are some) and do the processing:
if (headings.Count > 0)
{
var id = 1;
headingSummary.Append("<ol class=\"headings\">");
foreach (Match heading in headings)
{
var linkText = heading.Groups["linkText"].Value;
var level = decodeLevel(heading.Groups["level"].Value);
var summaryLink = $"<li><a href=\"#heading{id}\">{linkText}</a></li>";
var replacementLink = $"<h{level} x-data class=\"anchor\">{linkText}<a title=\"click to copy url\" x-on:click.prevent=\"copy($event.target)\" href=\"#heading{id}\" name=\"heading{id}\"><img src=\"/img/link.png\"/></a><span>url copied!</span></h{level}>";h{level}>";
headingSummary.Append(summaryLink);
content = content.Replace(heading.Value, replacementLink);
id += 1;
}
headingSummary.Append("</ol>");
var mt = input.GetContentProvider().MediaType;
return input
.Clone(new MetadataItems { { "HeadingSummary", headingSummary.ToString() } })
.Clone(context.GetContentProvider(content, mt))
.Yield();
}
If there are items this initialises the summary data with an ordered list to hold the headings. It also initialises a counter for an id for this heading. It iterates the discovered links, and then closes the ordered list. Finally it will return the modified data to the next step in the pipeline. That includes adding a
HeadingSummary
field to the metadata for the document containig the ordered list markup - which will be important in a bit.
The level of the heading needs parsing - since it might be a series of
#
characters from markdown or a number from the HTML. That logic is:
private int decodeLevel(string value)
{
int level = 0;
if(!int.TryParse(value, out level))
{
level = value.Length;
}
return level;
}
The loop extracts the groups for "linkText" and "level". It generates an
<li/>
element for the headings summary using the id from above and the "linkText" group to generate the
href
and the body of the link. Then it replaces the heading in the post's content with a new
<h?/>
element that uses the level computed above. And it includes both an
href
and a name` attribute on a link inside the heading, so that you can link directly to the heading.
url copied!
The changes to the headings in the content will render automaticall, because they're part of the page content.
In the razor that generates the right column of the site it can retrieve the metadata saved above, and render that out. Retrieving it is simple:
var headingSummary = Document.GetString("HeadingSummary");
var addHeadingSummary = !string.IsNullOrWhiteSpace(headingSummary);
And then rendering depends on whether
addHeadingSummary
is true (which means there was a summary to render):
@if (addHeadingSummary)
{
<section class="md:flex-2 md:flex-grow md:flex-shrink mb-2">
<h3 class="bg-gray-300 p-2 md:border-r-2 md:border-white lg:border-r-0 whitespace-nowrap">Post Headings</h3>
<div class="bg-white p-2 flex flex-wrap">
@Html.Raw(headingSummary)
</div>
</section>
}
Which just wraps the generated HTML from the metadata with some formatting to make it match the style of the right column entries.
And there's a bit of CSS to make everything look pretty.
url copied!
Now, can you spot the problem with the code above?
I'll admit I didn't think of this until I compiled and ran all the bits above. But there is an issue which I spotted once I had a draft of this post in place. This code finds all the headings - and it doesn't care if they're inside a code block or not:
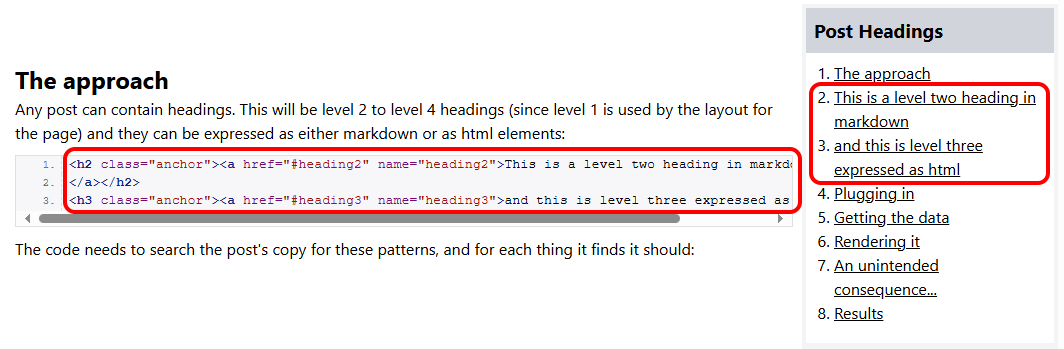
So with my first pass at the code, this blog post got messed up by the heading extraction. That code block of examples above with two headings in it got processed as well as the headings in the body text. The code block got rewritten and the headings got included in the right column summary even though they shouldn't have been.
Clearly not good. So what can be done to fix this?
My first guess was "can I make the regular expression that finds headings ignore them if they're inside a code block". I spent a chunk of time on this, and initially looked at using look-ahead and look-back expressions to say "try match the heading, but ignore if if there's a code fence before and after". But it turns out that doesn't entirely work. Look-ahead / look-behind expressions can't match arbitrary-length expressions - so having "match any set of characters ending with a code fence" doesn't actually work here. That makes sense when you think about how Regex engines work, but it's is a limitation here.
So my second attempt at this went for a simpler approach: Match the headings. Then separately match any fenced code blocks. And that requires a very simple expression added:
private static Regex _codeblocks = new Regex("```.*?```", RegexOptions.Compiled | RegexOptions.Singleline);
Then as you iterate the headings, skip any which are inside one of the matched code blocks. That code ends up modifying the loop that processes the matched headings to:
if (input.Source.Extension == ".md" && input.Source.FullPath.Contains("/posts/"))
{
var headingSummary = new StringBuilder();
var content = await input.GetContentStringAsync();
var headings = _headings.Matches(content);
var blocks = _codeblocks.Matches(content);
if (headings.Count > 0)
{
var id = 1;
headingSummary.Append("<ol class=\"headings\">");
foreach (Match heading in headings)
{
bool skip = false;
foreach(Match block in blocks)
{
if(heading.Index > block.Index && heading.Index < block.Index + block.Length)
{
skip = true;
break;
}
}
if(skip)
{
continue;
}
var linkText = heading.Groups["linkText"].Value;
var level = decodeLevel(heading.Groups["level"].Value);
var summaryLink = $"<li><a href=\"#heading{id}\">{linkText}</a></li>";
var replacementLink = $"<h{level} x-data class=\"anchor\">{linkText}<a title=\"click to copy url\" x-on:click.prevent=\"copy($event.target)\" href=\"#heading{id}\" name=\"heading{id}\"><img src=\"/img/link.png\"/></a><span>url copied!</span></h{level}>";
headingSummary.Append(summaryLink);
content = content.Replace(heading.Value, replacementLink);
id += 1;
}
headingSummary.Append("</ol>");
var mt = input.GetContentProvider().MediaType;
return input
.Clone(new MetadataItems { { "HeadingSummary", headingSummary.ToString() } })
.Clone(context.GetContentProvider(content, mt))
.Yield();
}
}
So wherever a heading overlaps a code block, that heading is skipped over. And while less efficient overall, that does work as originally intended.
url copied!
As you can see on this page all the headings in the body have a hover effect to identify that they can be linked to directly, and the right column includes a "Post Headings" region which lets you link to a particular heading. And that is pretty much what I wanted out of this bit of work. (I also did a bit of CSS & JS fiddling as well so that the hover effect allows copying the URL with a click, but that's less interesting, so I've not written it up)
Success I think.
↑ Back to top
