
Jeremy Davis
Sitecore, C# and web development
There are certain "rules of programming" that I keep hearing about in my career. One that came up in an interesting work debate recently was "you should never use regular expressions to parse HTML". Don't get me wrong - there can be a lot of useful knowledge wrapped up in these rules, but should we always follow them to the letter? I think it's an interesting question...
 url copied!
url copied!
The debate started because I was talking about some of the tooling I've hacked up for this blog. I've made an editor for it, which integrates and automates a collection of useful tasks to save me time. One of the key ones is that I have a "validate" button, which will read through the markdown file for a post and warn if there are any important things I've forgotton to do:
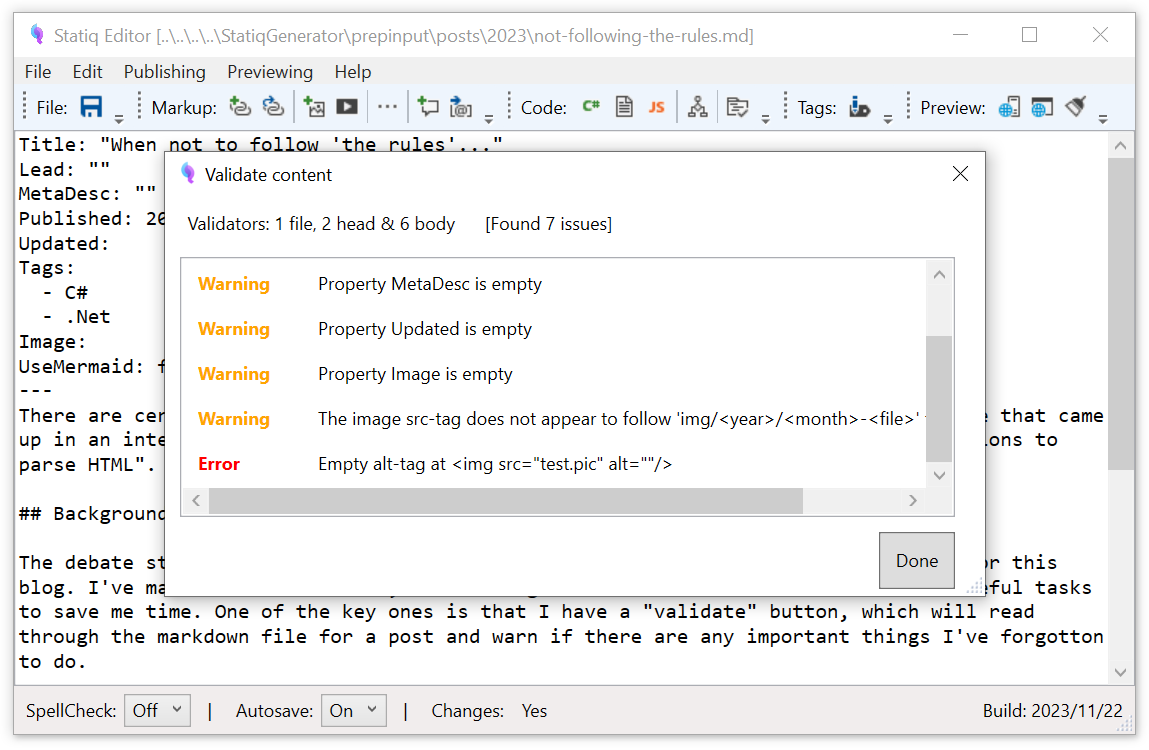
One of the key validations I've built is "do all the images have alt-tags". (It's the last one in the screenshot above) To have better control over the mark-up that gets rendered I tend to do images as HTML rather than as Markdown when I write. (And I have some editor helpers for that - including generating HTML when I paste or drag/drop image data or files) So testing for alt-tags requires parsing out bits of HTML embedded in the markdown and then checking it has the right attributes filled in.
When I implemented this, I wrote validation using regular expressions.
And I can almost hear the intake of breath from some quarters as I type that...
url copied!
The reason why there's a general "don't parse HTML with regular expressions" is that HTML is a tree of data. By definition there is nesting of elements, to build up the structure of a document. The standard has rules for what elements are supposed to be allowed to nest under which others, but broadly the structure ends up looking like this in diagram form:
flowchart LR html --> head head --> title html --> body body --> h1 body --> p1 p1[p] --> b body --> img body --> p2[p] p2 --> span body --> p3[p]
Mechanisms for querying trees allow you to express that heirarchy directly. A good example here is xPath, where you might write
div//img
to select all the images which are a descendent of a div element.
But regular expressions don't have a way to represent tree-like data in their matching rules. You can specify the order you expect text to come in, like
s.{2}ing
to match
sewing
or
siding. But you can't model the parent-child type of behaviour that HTML is really based on, so expressing that xPath query can't work easily. It's quite easy for an attempt to match "this image is a descendant of a div" to also catch "this image comes after a div in the stream of markup, even if it's outside all the divs". And even if you do manage to get something fairly accurate it will end up way more complicated than the xPath equivalent.
So it makes sense that as a developer community we have this advice to avoid regular expressions with HTML.
url copied!
So we can't reliably use regular expressions to parse trees, but that doesn't mean they're always useless here. The key thing for my use-case is that I didn't actually care about the tree structure.
The verification I needed to create cared about the existence of an image element, and what attributes it contained. But it didn't care what the actual position of the image was in the overall document. So there wasn't a need for a tree-like query.
So this seemed like a reasonable use case for regular expressions.
url copied!
Just because regular expressions can work here, doesn't automatically mean they'd be good. We've already noted that xPath would be some developers approach. So why not pick that way?
Well the best way to consider things like this is usually to mock up a little test to compare approaches against each other. So I sat down and tried to implement that same "parse out the alt attribute from images" logic in the common approaches in C#.
Out of interest, I decided to try all the obvious patterns I could think of:
[Benchmark]
public void NewRegex()
{
var re = new Regex(Expression);
var results = re.Matches(DataSource.Data);
// do something
}
Regex
class for each match.[Benchmark]
public void RegexDotMatches()
{
var results = Regex.Matches(DataSource.Data, Expression);
// do something
}
private readonly static Regex CompiledRegex = new Regex(Expression, RegexOptions.Compiled);
[Benchmark(Baseline = true)]
public void StaticNewRegex()
{
var results = CompiledRegex.Matches(DataSource.Data);
// do something
}
[GeneratedRegex(RegexTests.Expression, RegexOptions.Singleline)]
private static partial Regex parser();
[Benchmark]
public void GeneratedRegex()
{
var re = parser();
var results = re.Matches(DataSource.Data);
// do something
}
[Benchmark]
public void HtmlAgility()
{
HtmlDocument xd = new();
xd.LoadHtml(DataSource.Data);
var result = xd.DocumentNode.SelectNodes(RegexTests.AgilityPackQuery);
// do something
}
XmlDocument
class and using xPath for each match.[Benchmark]
public void XmlDocument()
{
XmlDocument xd = new();
xd.LoadXml(DataSource.Data);
var result = xd.DocumentElement.SelectNodes(RegexTests.XPathQuery);
// do something
}
I included these four different approaches to using Regular Expressions to see if those they had different memory or CPU implications at runtime. And the two xPath approaches for similar reasons, and to consider if "cope with non-XHTML" made a significant difference here.
Running those as a Benchmark.Net console app I got:
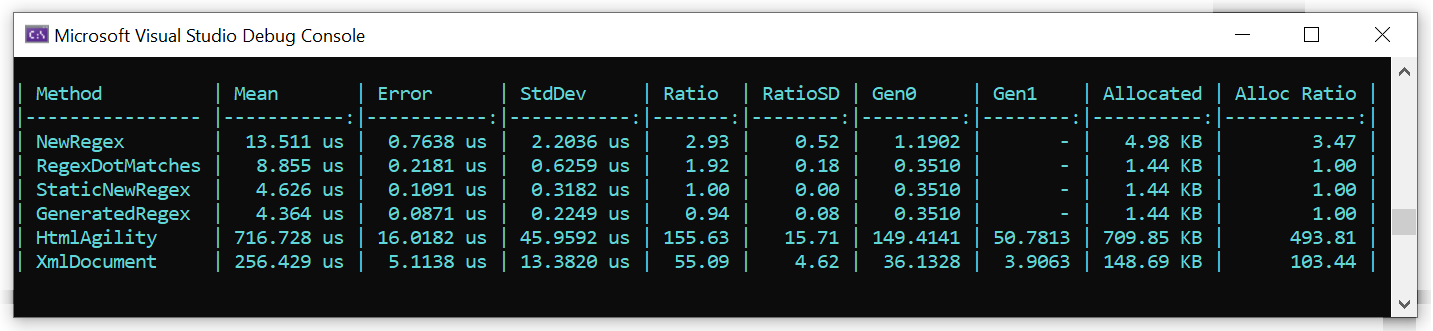
To summarise the key data there in a readable form:
| Test Name | Mean Time Taken | Memory Allocated |
|---|---|---|
| New Regex | 14us | 5KB |
| Regex Dot Matches | 9us | 1.4KB |
| Static New Regex | 5us | 1.4KB |
| Generated Regex | 4us | 1.4KB |
| Html Agility Pack | 727us | 799.9KB |
| Xml Document | 256us | 148.7KB |
So it's pretty obvious from this why Regular Expressions might be a good idea here. Parsing the data using the HTML Agility Pack may be resilient but it's dramatically slower and allocates a lot more memory. And while the XML Parser is better than the agility pack, it's still fairly bad when compared to the Regular Expression approaches. The ability to accurately model and query a tree structure does come with some trade-offs at runtime.
The other thing of note here is that creating a new regular expression object for each pass through the parsing test is a bit slower than using generated or static options. But its less than I had expected it to be. The internal caching that .Net does when running regular expressions is cleverer than I'd thought. And in all the cases here, the allocations for the Regular Expression are much smaller than I'd expected.
url copied!
I'd argue we shouldn't ignore the "rules" that get promoted about programming practice. They do tend to have good reasons behind them, and in many scenarious they will guide you towards better solutions.
But at the same time, try to avoid applying them without thinking about where they came from, and whether the theory they're based on is relevant to your particular problem.
And (to me at least) the single most important thing about making decisions about your code is to have evidence for which approach to choose. Write simple but relevant tests, measure their results and compare the approaches. If nothing else, they give you things to point to in code reviews to show that you have justification for your choices.
Having that evidence is the key thing to help you decide if those important rules are right for what you're doing...
↑ Back to top
