
Jeremy Davis
Sitecore, C# and web development
Some time back, when I was looking at how to release containerised Sitecore into Azure Kubernetes Clusters, I worked through the question of "how do I make DevOps wait for the new images to be deployed", because you might want to run further work after the new containers are spun up. While what I tried back then was mostly working, I've found some reasons to try a different tack since then.
 url copied!
url copied!
kubectl.exe wait --for=condition=Ready pods -l app=cm -n <YourNamespace> --timeout=2700s
That seemed to be working OK for a while – but recently I've seen some issues. On some deployments I'd do a release in DevOps which would complete ok, but when I went to smoke-test it afterwards it would be clear that the Unicorn updates were missing. This was odd, as I could see the DevOps logs saying that the step which fired off the Unicorn sync had completed ok:
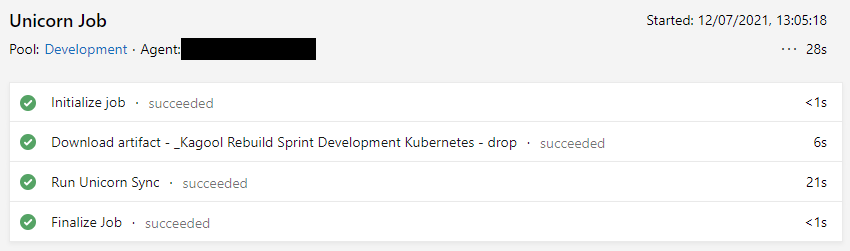
It took me a while to realise that while that step was completing OK, the detailed log for the step showed that the sync had run, but had no changes to apply. And that was clearly wrong – my release definitlely included changes. And if I subsequently went to the Unicorn UI via the Sitecore CM, running "sync everything" from there would do the updates I was expecting.
After a certain amount of thinking, it struck me that the most obvious solution to the quandry was "the sync has run on a CM pod which has not been upgraded to the new image". That explains the odd behaviour – if sync ran on an old CM image it would indeed have no changes to apply. But why would it be doing that – DevOps is waiting for the new CM image to be ready before it tries the Unicorn sync.
The answer to that was kind of obvious in retrospect. When I sat back and thought about all the deployments I was doing, I could see a clear pattern:
And that lead me to understand what was up:
The wait command above works fine when you are releasing a change to a single CM pod. But if you have multiple pods, it can go wrong: The "wait" can complete when only one of the pod replicas has been updated, which means you have a roughly 50% chance that the HTTPS request to sync Unicorn gets routed through the ingress controller to an old pod, rather than a newly updated one.
So how can DevOps ensure that all of the CM pods have been updated before it tries the Unicorn Job?
url copied!
kubectl.exe rollout status deployment cm -n <YourNamespace>
By default that command will keep waiting until all the changes from an "apply" operation for a deployment called "cm" have finished. Which should include any replicas spinning up.
But it's worth noting that timeouts behave differently here than they do with the "wait" command above. In the original pattern, you passed a timeout flag on the command line, kubectl.exe would wait for "the pod to be ready, or that timeout to expire". The "rollout" command doesn't work that way. There's no command line parameter to control the timeout. It is done via the yaml file for the deployment, using a parameter called "progressDeadlineSeconds". It took me a while to get this one right, as the docs say "it's a child of the spec node", but aren't entirely clear which one, because your yaml probably includes more than one. It's the highest level "spec" that needs this setting:
apiVersion: apps/v1
kind: Deployment
metadata:
name: cm
labels:
app: cm
spec:
replicas: 2
progressDeadlineSeconds: 1800
selector:
matchLabels:
app: cm
template:
metadata:
labels:
app: cm
spec:
nodeSelector:
kubernetes.io/os: windows
initContainers:
- name: wait-xdbcollection
image: mcr.microsoft.com/powershell:lts-nanoserver-1809
command: ["pwsh", "-Command", "do { Start-Sleep -Seconds 3 } until ($(try {(iwr http://xdbcollection/healthz/ready).StatusCode -eq 200} catch { $false }));"]
... etc ...
The "progressDeadlineSeconds" value controls how long the Kubernetes control code waits for the deployment to complete before it's declared to be in an error state. If that occurs the wait will end and report that error. What happens to the deployment seems to depend on what caused it to take that long. If it's actually failing (maybe the image can't be downloaded?) then the deployment won't complete. But if it's hit that timeout because it's just taking longer, then the deployment will probably finish ok despite the wait receving the "error" state for its length.
I've done a few test deployments with this alternative pattern, and they've worked ok. But I think I need to run more real deployments before I'll be confident it is all better. More to come, perhaps...
↑ Back to top
