
Jeremy Davis
Sitecore, C# and web development
This is post 3 of 3 in a series titled Driving browsers
- Driving browsers: #1 The Browser
- Driving browsers: #2 The state machine
- Driving browsers: #3 The states
Time for the final part of my series on controlling a web browser. With code to load a browser, and the overarching State Machine to control it, this part finishes off with the code for some states to load a page and extract its markup. Plus a few conclusions...
So with the framework in place, now we need to implement some states the code is going to work through. Having done a bit of digging into how DevTools API allows the browser to be controlled, the flow for fetching all the HTML from a page might look like:
flowchart LR A[Enable Page
Events in the
browser] B[Navigate to
the target page] C[Fetch the root
ID of the document's
markup] D[Get the
outer HTML] A-->B B-->C C-->D
 url copied!
url copied!
First thing is the browser needs to be told to return state events so that we can detect when page loading has finished. Then it can tell the browser to navigate to a page. Once that completes you need to get the internal ID of the document root, and then use that ID to fetch the outer HTML of that node.
(There are loads of other commands and events that you can deal with, but these are enough for a demo)
As noted above, all the states are instances of the
State
class, so the code for the first "Enable Page Events" state looks like:
public class PageEventEnableState : State
{
public static State Instance { get; } = new PageEventEnableState();
private static readonly int _id = 1;
public override async Task Enter(StateMachine owner)
{
var request = new PageEventEnableParameters();
await owner.SendCommand(request, _id);
}
public override async Task Update(StateMachine owner, DebuggerResult data)
{
if (data != null && data.Id == _id)
{
owner.TransitionToNewState(PageNavigateState.Instance);
}
}
public override async Task Leave(StateMachine owner)
{
}
}
This defines a static instance of the state which is used to select states. (As noted before, these classes have no internal data, so they're safe to reuse across operations) It also defines an integer "id" for this operation. That gets passed into any command we send, and comes back in the response, to help us decide which responses come from which calls.
The
Enter()
method creates the data for the call, and then asks the owning
StateMachine
to issue the command to the connected browser. As mentioned before, we need an instance of the
IDebuggerCommandProperties
interface to help format the parameters for sending. In this case it's trivially simple as there are no extra parameters to the "Page.enable" call:
public class PageEventEnableParameters : IDebuggerCommandProperties
{
public string CommandName => "Page.enable";
}
With that sent, any messages received by the
StateMachine
get routed to the
Update()
call. And to decide when we're done with this state we wait for a response which has data, and where the returned
Id
equals the one we passed in. When we see that, the
StateMachine
can be instructed to move to the next state.
And
Leave()
has nothing to do here...
url copied!
Now that our code will be notified of navigation events like "the page is loaded now", it can move on to loading the right page. The code for this adds a few extra bits:
public class PageNavigateState : State
{
public static State Instance { get; } = new PageNavigateState();
private static readonly int _id = 2;
public override async Task Enter(StateMachine owner)
{
var nextUrl = (string)owner.State["nextUrl"];
var request = new PageNavigateParameters() { Url = nextUrl };
await owner.SendCommand(request, _id);
}
public override async Task Update(StateMachine owner, DebuggerResult data)
{
if (data != null && data?.Method == "Page.loadEventFired")
{
owner.TransitionToNewState(FetchDocumentRootState.Instance);
}
}
public override async Task Leave(StateMachine owner)
{
}
}
So again we define the instance of the state, and an ID. Turns out that step ID isn't so important here, however.
The
Enter()
command needs to send the URL and a Referrer for the navigation request. This code is ignoring Referrer as it's not really relevant for this operation. But since the state can't store its own data, it needs some help to fetch the URL it should be navigating too. There are multiple ways to solve this, but for simplicity I picked the "give the
StateMachine
a dictionary of state data which the
State
objects can access" approach. So the URL to use gets picked out of there, and stuck into the
IDebuggerCommandProperties
instance for this call:
public class PageNavigateParameters : IDebuggerCommandProperties
{
public string CommandName => "Page.navigate";
public required string Url { get; set; }
public string Referrer { get; set; } = string.Empty;
}
The "Page.navigate" call does have some other optional parameters, but they weren't relevant here.
The
Update()
behaviour here is a little different, because navigation triggers a boat-load of responses to the WebSocket. The response we care about is "the page has finished loading" however, and not "I have accepted the navigation request ok" or any of the other "stuff is changing" messages which get sent back. Hence the test for moving to the next state doesn't actually care about the ID of the request we sent originally. Instead it looks for a message of type "Page.loadEventFired" being returned. That does return some data (the time for the event) but that's not relevant so isn't processed.
But that event arriving means the browser has a new document loaded, and the
StateMachine
can move on:
url copied!
Inside the browser's model for the DOM, individual nodes get an ID assigned, which this API can use to access specific bits of data. So if the code wants to retrieve data for a specific node, it first needs to find the node's ID. There are methods for searching the DOM to find nodes, but in this case the root is all we need, and that has a specific command.
So the next
State
can issue that request, and wait for a response:
public class FetchDocumentRootState : State
{
public static State Instance { get; } = new FetchDocumentRootState();
private static readonly int _id = 3;
public override async Task Enter(StateMachine owner)
{
var request = new FetchDocumentRootParameters() { };
await owner.SendCommand(request, _id);
}
public override async Task Update(StateMachine owner, DebuggerResult data)
{
if (data != null && data.Id == _id)
{
var nodeId = data.Result?["root"]?["children"]?[1]?["nodeId"]?.GetValue<int>() ?? -1;
owner.State["NodeID"] = nodeId;
owner.TransitionToNewState(GetOuterHtmlState.Instance);
}
}
public override async Task Leave(StateMachine owner)
{
}
}
So as before
Enter()
is sending off an
IDebuggerCommandProperties
object that specfies we want to run the "DOM.getDocument" command. This returns basic internal data about nodes in the DOM, and has a couple of extra parameters:
public class FetchDocumentRootParameters : IDebuggerCommandProperties
{
[JsonIgnore]
public string CommandName => "DOM.getDocument";
public int Depth { get; set; } = 1;
public bool Pierce { get; set; } = false;
}
The
Depth
property lets us specify how many layers of children to get data for. We only care about the root item, so that means we want one layer. The
Pierce
property lets you specify the browser should look into things like
IFrame
elements when processing - which isn't relevant here, so is left turned off.
Here the
Update()
method is looking for the
ID
sent in again, it cares about the response to the specific request sent. And it gets back some data as a
JObject. The code here is extracting the
int
value of the
nodeId
property for the item we want. That's probably not the safest way of working here, (it should really handle nulls or unexpected values in that object tree) but it gets the job done for a demo...
The next step is going to need this ID, so it gets written into the
StateMachine
object's data store for the next operation to pick up.
url copied!
Now that the code has an ID for an element it can ask for the HTML for it:
public class GetOuterHtmlState : State
{
public static State Instance { get; } = new GetOuterHtmlState();
private static readonly int _id = 4;
public override async Task Enter(StateMachine owner)
{
var nodeId = (int)owner.State["NodeID"];
var request = new GetOuterHtmlParameters() { NodeId = nodeId };
await owner.SendCommand(request, _id);
}
public override async Task Update(StateMachine owner, DebuggerResult data)
{
if (data != null && data.Id == _id)
{
var html = data?.Result?["outerHTML"]?.GetValue<string>() ?? string.Empty;
owner.State["HTML"] = html;
owner.TransitionToNewState(NullState.Instance);
}
}
public override async Task Leave(StateMachine owner)
{
}
}
And this is very similar to the previous states. It sends the
IDebuggerCommandProperties
which specify a call to the "DOM.getOuterHtml" method, passing the
NodeId
from the previous step, retrieved from the
StateMachine
data.
public class GetOuterHtmlParameters : IDebuggerCommandProperties
{
[JsonIgnore]
public string CommandName => "DOM.getOuterHTML";
public required int NodeId { get; set; }
}
And when the correct response ID comes back, the resultant HTML gets passed back to the
StateMachine.
url copied!
The final state needs to signal "done now" to the
StateMachine, and as mentioned in the previous episode, that's done with the "null" state:
public class NullState : State
{
public static State Instance { get; } = new NullState();
public override async Task Enter(StateMachine owner) { }
public override async Task Update(StateMachine owner, DebuggerResult data) { }
public override async Task Leave(StateMachine owner) { }
}
It's an instance of a
State
but it does nothing, and lets the
StateMachine
detect that the state flow is done. (Which is basically an instance of the
Null Object
pattern)
url copied!
So all that's left now is a bit of controlling code which makes use of all the stuff discussed so far. And that's fairly simple:
using (var browser = BrowserFactory.Create())
{
browser.Open("about:blank");
var connection = await browser.Connect();
var stateMachine = new StateMachine(PageEventEnableState.Instance, connection);
stateMachine.State["nextUrl"] = "https://bbc.co.uk/news/";
await stateMachine.Start();
await stateMachine.Wait();
var html = stateMachine.State["HTML"] as string;
Console.WriteLine($"HTML: {html}");
}
It creates the
Browser
object, opens the window and connects to the DevTools API. Then it passes in the URL to request and sets the state machine going. After waiting for it to complete, it gets back the resultant markup.
So running this code gets a browser window to pop up briefly:
And the console window will list out the HTML from the page that got loaded:
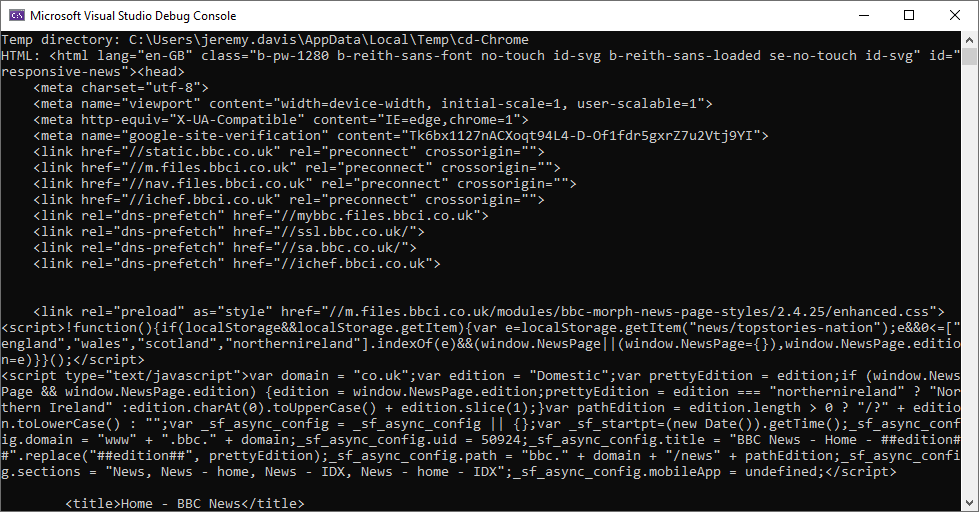
Success!
The code for all this is available in a GitHub repository, if you want to play with it.
url copied!
This has been an interesting coding diversion - and one that's solved a real-world problem for me. The markup I needed to scrape that didn't work with a plain
HttpClient
does work with this approach.
But there are a couple of down-sides to this approach:
I've also noticed one interesting problem with this code. In some circumstances the code above will fail to automate the browser correctly. If the browser starts up in some sort of "ask questions to set up your profile" mode (particularly likely with Edge if it creates a new profile folder or if it gets a big security update) then it doesn't seem to allow connections to the DevTools API. Answering the questions and re-running the code seems to sort this - but it's not ideal for an automation situation. I've not found an automatic way around this issue yet - but it's possible one exists.
But implementing this has certainly given me some interesting insight into how code for front-end testing frameworks gets built. And it shows an interesting example of how the state-based design patterns can be used in the real world.
Is it the best way? Probably not. But it's an interesting demo of one way to keep logic for individual steps in a process separate from the overall orchestration of the process. And it does this in a very different way to the more pipeline-based approaches I've written about before.
Though in getting to the end of this I realise the
Leave()
step isn't really relevant to the particular work I was doing and could be removed - but maybe it is helpful in your scenario...

