
Jeremy Davis
Sitecore, C# and web development
A while back I wrote about the transition from T4 templates to using Roslyn Source Generators for generating code in .Net Core solutions. While that worked for me, and I was able to get it to do what I needed, I was never really happy with all the output source as literal strings in the generator code. Recently I had another potential use for generated code, so I decided to try and fix this issue...
 url copied!
url copied!
Working through some "migrate old code to .Net 8", I was looking at a huge pile of nullability warnings for an API surface. I was considering how I might fix this, and as well as "just rewrite the code to not have nulls", I was considering having a "null object" approach. But there were a good collection of interfaces which would need that null object, so I found myself wondering if it would be possible to generate these objects without the need for me to write them all manually.
If the code contained an interface something like this, marked with an attribute to indicate it should be used to generate a new class:
[GenerateNullObject]
public interface INetwork
{
List<IConnection> CurrentConns { get; }
IConnection[] ConnectionSet { get; }
int Id { get; }
void Disconnect();
IConnection CreateConnection(int count, Regex r);
}
Perhaps it would be possible to construct a source generator which could read that and then output an appropriate null-object class that looked something like:
// <auto-generated />
namespace NullObjExperiment
{
using System.Text.RegularExpressions;
public class NullNetwork : INetwork
{
public static NullNetwork Instance { get; } = new NullNetwork();
public List<IConnection> CurrentConns { get; } = new List<IConnection>();
public IConnection[] ConnectionSet { get; } = Array.Empty<IConnection>();
public int Id { get; } = 0;
public void Disconnect()
{
return;
}
public IConnection CreateConnection(int count, Regex r)
{
return new NullConnection();
}
}
}
An object with a static "null object instance", and an implementation of all the other properties and methods which do nothing, but don't include any nulls.
The broad pattern here is pretty similar what I'd done previously with source generators. But I really wanted to experiment with not having big chunks of output source-code text in the generator for string concatenation. There are too many opportunities for mistakes and badly formatted output when the generator is littered with lines like:
outputString = $$"""
// <auto-generated/>
{{usingsList}}
namespace {{namespaceName}}
{
public class Null{{className}} : {{interfaceName}}
{
private static Null{{className}} _instance = new();
public static Null{{className}} Instance => _instance;
private Null{{className}}() {}
}
}
""";
I did a bit more googling about how to write source generators with this issue in mind. But I didn't find much content - all the examples I came across just did the string concatenation thing. So I had to do some digging to work out what to do next.
url copied!
Turns out that the parsed code model you get given when you're executing your source generator works both ways. These objects form the basis for the input to the generator via the
context.Compilation.SyntaxTrees
parser results. But they can also be used to build up the structure you want to output from your generator, and then work out the correct source code for you.
The object
Microsoft.CodeAnalysis.CSharp.SyntaxFactory
provides a collection of helper methods to help you build up your own tree, which can be used to output code. For example, if you wanted just a namespace in a file output by your source generator, you could write something like:
public class JustWriteANamespaceGenerator: ISourceGenerator
{
public void Execute(GeneratorExecutionContext context)
{
// Generate a namespace
var newTree = SyntaxFactory.NamespaceDeclaration(SyntaxFactory.IdentifierName("ExampleNamespace"));
// Turn the namespace into text
var source = newTree.NormalizeWhitespace().ToFullString();
// Output it into the compilation process
context.AddSource($"ExampleNamespace.g.cs", SourceText.From(source, Encoding.UTF8));
}
public void Initialize(GeneratorInitializationContext context)
{
}
}
And the file output would contain:
namespace ExampleNamespace
{
}
(Note that most documentation examples of using these APIs make use of a
using static
statement to get rid of the need for
SyntaxFactory.
before each of the helper methods. While that does make the code shorter, I've skipped it here because it makes small examples less obvious I think)
So that solves the problem of messy string processing, but it does hint that the code might get pretty verbose for generating anything complicated. The model in the syntax tree is detailed, and it's not necessarily easy to work out what structure you actually want to be building up...
url copied!
Step forward helpful tooling! Some of my googling around this came up with this website: https://roslynquoter.azurewebsites.net/. One of the features of this is that it can take a chunk of code (which doesn't have to be a complete compilable file) and generate the syntax tree for it. That lets you see what structure the compiler generates for the code you want, which can be very helpful to work out what you want to construct for your output code...
So for example, the simple generated above gives:
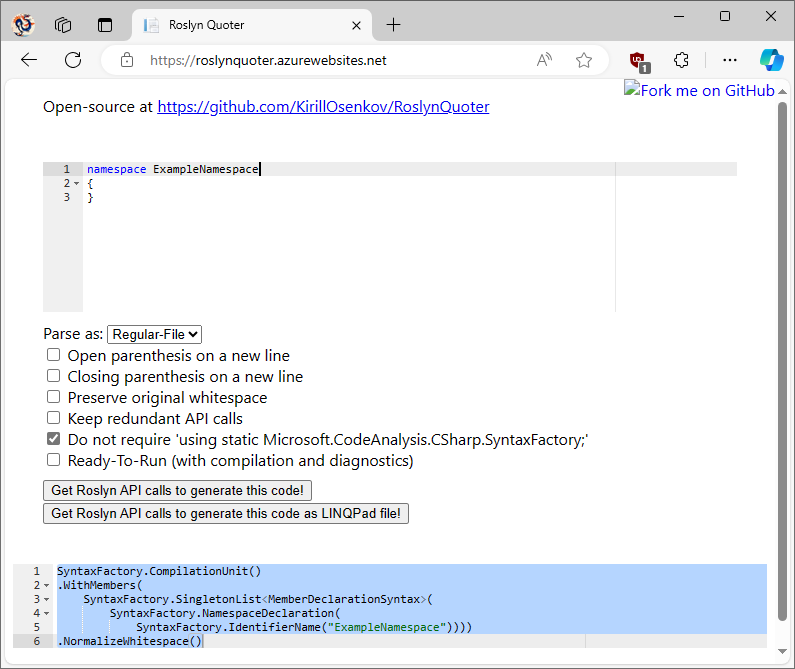
It does tend to show a chunk of stuff you don't necessarily need in a given situation - Like the
CompilationUnit
and
SingletonList<>
in the example above compared to the example code previously. But it definitely makes working out the core of the code required much easier.
url copied!
So sitting and working through an example, the broad pattern for the code is:
using
statements requiredTasks like extracting the right
using
and
namespace
declarations can basically copy these things from the input code. It can take the discovered interface's declaration, and look up the syntax tree to find the right elements:
private IEnumerable<UsingDirectiveSyntax> FetchUsings(InterfaceDeclarationSyntax mi)
{
return mi.Ancestors().Last().ChildNodes()
.Where(n => n is UsingDirectiveSyntax)
.Select(n => n as UsingDirectiveSyntax);
}
but other tasks require generating code more directly. For example the static instance:
private PropertyDeclarationSyntax GenerateStaticInstance(string className)
{
return SyntaxFactory.PropertyDeclaration(
SyntaxFactory.IdentifierName(className),
SyntaxFactory.Identifier("Instance")
).WithModifiers(
SyntaxFactory.TokenList([SyntaxFactory.Token(SyntaxKind.PublicKeyword), SyntaxFactory.Token(SyntaxKind.StaticKeyword)])
).WithAccessorList(SyntaxFactory.AccessorList(
SyntaxFactory.SingletonList<AccessorDeclarationSyntax>(
SyntaxFactory
.AccessorDeclaration(SyntaxKind.GetAccessorDeclaration)
.WithSemicolonToken(SyntaxFactory.Token(SyntaxKind.SemicolonToken))
))
).WithInitializer(
SyntaxFactory.EqualsValueClause(
SyntaxFactory.ObjectCreationExpression(
SyntaxFactory.IdentifierName(className)
).WithArgumentList(SyntaxFactory.ArgumentList())
)
).WithSemicolonToken(SyntaxFactory.Token(SyntaxKind.SemicolonToken));
}
And that's a fairly good example of what the code can end up looking like - lots of nested business. So putting sensible chunks into separate methods that return parts of the required syntax tree can help to make the overall code a bit more readable. I suspect there's would be some mileage in creating extension methods to encapsulate some of the more common operations.
It's worth noting that while this approach does make it possible to write code without typos and spacing issues, you can absolutely still generate stuff where the generator compiles but the output doesn't. I bumped into this a few times while I was working through this example. Generating properties was the first place where it tripped me up. I was aiming to output something along the lines of:
public int SomeProperty { get; set; }
Initially I went down a bit of a rabit hole of "how do you generate this", because I could see how you create the accessors if you want a block of code attached to each (so
get { return something; }) but I could not see what to do if you wanted an auto-implemented property. The
SyntaxFactory
methods for creating property accessors has overloads which allow passing a semi-colon:
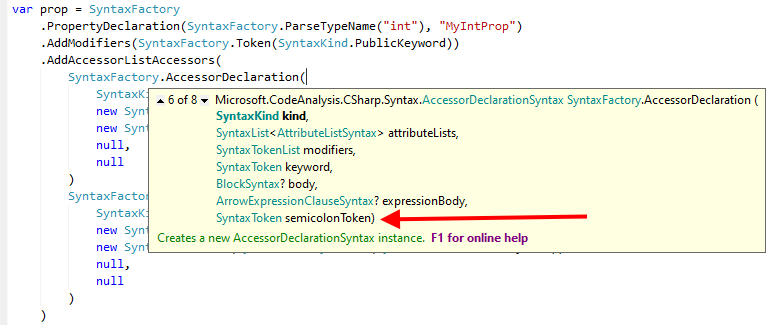
But that didn't do what I wanted, and caused me a good chunk of confusion. But the tooling above came to the rescue, as it helped me see that rather than this overload, what was missing was another extension method called
WithSemicolonToken(). That gets appended after the accessor (and in quite a few other places) to add in the correct data. An accessor ends up being created more like:
var setAccessor = SyntaxFactory.AccessorDeclaration(
SyntaxKind.SetAccessorDeclaration,
new SyntaxList<AttributeListSyntax>(),
new SyntaxTokenList(SyntaxFactory.Token(SyntaxKind.PrivateKeyword)),
null,
null
).WithSemicolonToken(SyntaxFactory.Token(SyntaxKind.SemicolonToken));
But the other thing I realised was that this didn't actually need doing at all. Since these syntax tree structures are immutable, they've been designed with fairly easy to use copy-and-modify behaviours. (Like I was doing with
using
/
namespace
above) So in reality I can could declare a concrete property by taking the parsed propery from the input interface, and modifying a copy using some
.WithSomething()
methods:
private PropertyDeclarationSyntax GenerateProperty(PropertyDeclarationSyntax p)
{
return p
.WithModifiers(new SyntaxTokenList(SyntaxFactory.Token(SyntaxKind.PublicKeyword)))
.WithInitializer(SyntaxFactory.EqualsValueClause(FetchInitialiser(p)))
.WithSemicolonToken(SyntaxFactory.Token(SyntaxKind.SemicolonToken));
}
The
.WithModifiers()
method adds in the
public
modifier that the concrete property needs. The
.WithInitializer()
adds the initialised value for the property, so it doesn't start out null. And there's another example of
.WithSemicolon()
to round it off. And that (with the
FetchInitialiser()
method I'll get to later, can end up with a property that looks like:
public IConnection[] ConnectionSet { get; } = Array.Empty<IConnection>();
Now that
FetchInitialiser()
bit there is perhaps one of the places where this whole approach becomes a bit tricky. It's there to look at the type of a property and work out the right initialiser expression. It's generating the
= Array.Empty<IConnection>()
bit of the property above - where the default value of the property is being set.
The fun bit of this is that it has to cope with a big old range of possible types, and what different initialisers they need. As examples, you might have numeric types, strings, simple objects, objects with constructor parameters, collections and objects which use generics. Plus some of these may be "normal" objects and some might be things which the code is also generating null-objects for.
My first pass through this code (which ignored some of these possibilities) ended up as a bit of a mess of
switch
and
if
statements:
private ExpressionSyntax FetchInitialiser(PropertyDeclarationSyntax p)
{
var type = p.Type;
if(p.Type is PredefinedTypeSyntax pdt)
{
switch(pdt.Keyword.Kind())
{
case SyntaxKind.StringKeyword:
return SyntaxFactory.LiteralExpression(SyntaxKind.StringLiteralExpression, SyntaxFactory.Literal(""));
case SyntaxKind.IntKeyword:
return SyntaxFactory.LiteralExpression(SyntaxKind.NumericLiteralExpression, SyntaxFactory.Literal(0));
default:
break;
}
}
else if(p.Type is GenericNameSyntax gns)
{
return SyntaxFactory.ObjectCreationExpression(
SyntaxFactory
.GenericName(gns.Identifier)
.WithTypeArgumentList(
gns.TypeArgumentList
)
).WithArgumentList(SyntaxFactory.ArgumentList());
}
else if (p.Type is ArrayTypeSyntax ats)
{
return SyntaxFactory.InvocationExpression(
SyntaxFactory.MemberAccessExpression(
SyntaxKind.SimpleMemberAccessExpression,
SyntaxFactory.IdentifierName("Array"),
SyntaxFactory
.GenericName(SyntaxFactory.Identifier("Empty"))
.WithTypeArgumentList(
SyntaxFactory.TypeArgumentList(
SyntaxFactory.SingletonSeparatedList<TypeSyntax>(
ats.ElementType
)
)
)
)
);
}
return SyntaxFactory.LiteralExpression(SyntaxKind.DefaultLiteralExpression, SyntaxFactory.Token(SyntaxKind.DefaultKeyword));
}
That's covering "predefined types" like string and integer, Generic types with a parameterless constructor and only one generic parameter, and single dimensional arrays. Anything else just gets a value of
default
- which works for some things (like
float
or
double) but doesn't work for
int[,]
or other more complex types. Since this was a hacky experiment, I only looked at the ones that were relevant to my test.
Now this code could definitely be tidied up - the different return statements should really be broken out into functions to neaten things up for a start) but it shows the complexity fairly well. The challenge is that there are a lot of possibilities to cover. And this is only one location where it's needed - the return values of method declarations need something fairly similar too. (Which again, I kind of skipped over in my tests)
The code above is just extracts from my experiments. I've put a more complete example in a github repository, if you want to look at it in more detail, as this post would have been way too long with all that included.
url copied!
Does it work? Yes, sort of. I got a subset of my null objects to build and compile. Could it work properly? Yes, with effort I could have added the rest of the logic required I think.
But the code to achieve this does end up pretty complex and it would be quite a lot of effort to produce. Between the wordy code to generate output, and the need to cover all the possible data types it might process in my scenario, it's not a simple bit of code.
Overall I think that writing the code-generation with factory methods rather than strings does have advantages in terms of quality, and the ability to "nest" processing of elements by passing syntax trees around. Plus I think this approach would be better if you wanted to unit test your code properly. But it takes a lot longer than just writing the strings. So there's an effort trade-off there. I suspect this is why all the example code I read stuck with the strings - it's just easier to do and read if you're aiming for something quick and easy.
In the end I decided not to pursue this approach in the code I'd been working on - but it was an educational diversion none the less...
↑ Back to top
