
Jeremy Davis
Sitecore, C# and web development
It struck me recently that there are a few places in this blog where I linked to pages I know will disappear over time. The examples that started me thinking about this were the Symposium and SUGCON websites that get published each year. They tend to reuse the same domain names from year to year without archiving the old content. So those links go stale fairly quickly, and posts from years back now point to this year's events by default. So I started wondering if I could fix this issue automatically...
 url copied!
url copied!
The idea that I had was this: If I know links would expire in a certain timeframe, I could add some metadata about those dates to the links in my blog's source data. Then each time I republish my blog, the site generator code could look for this metadata, and filter out the links if they had expired. Not an instant fix - but given publishing schedules, likely good enough for my scenarios.
So I could write content like:
This is <span class="rx">a link which should have gone<a class="expired" href="#expired">**1</a><a name="removed1"></a><span> </span></span> by now. But <a href="https://test.com">this one should always stay</a> visible.
And when Statiq runs, it can look for the
until
attribute on links, and remove those links if their date is in the past.
url copied!
This is fairly easy to achieve in Statiq. So I've hacked up a first pass at a prototype to try this out with:
This seems like a "change the incoming data" scenario, rather than something that should happen in the Razor templates which render the content in pages. The pipelines which run during the publish process give us a convenient point to extend the code which pulls in content to enable this. The configuration of the pipelines can be extended by adding a configurator:
public class ExpiringLinkConfigurator : IConfigurator<Bootstrapper>
{
public void Configure(Bootstrapper configurable)
{
configurable.ModifyPipeline("Content", p => {
p.ProcessModules.Insert(4, new ExpiringLinkProcessor());
});
}
}
This code needs to modify the content being imported, so the "content" pipeline is the right one. Working out where in that flow to insert a change involves a bit of digging about - but broadly here "after everything's loaded, and my other content customisation ran" is fine here. The source for how the default pipelines are configured is available on Github, so it's easy enough to look at the order of execution to work this out.
And that the actual processor is defined as:
public class DisappearingLinkProcessor : ParallelModule
{
protected override async Task<IEnumerable<IDocument>> ExecuteInputAsync(IDocument input, IExecutionContext context)
{
// Logic goes here
}
}
No two posts depend on each other, so this processing can run as a
ParallelModule
and changes can happen to multiple site content items at once. That makes the changes this makes more efficient in the overall site generation process.
The logic here needs to do three things:
until
attribute, and if so parse it out.until
attribute and continue to the next link to check.Checking for markdown is easy:
if (input.Source.Extension == ".md")
{
// carry on
}
return input.Yield();
The
IDocument
input has an
Extension
property to check, in order to look only at the markdown files - posts etc. And this input isn't being processed then the original data can be returned out of this pipeline processor.
Finding links can be done with a pattern I've used elsewhere in my blog editor code: Regular expressions can fairly efficiently find the relevant things. Yes, this could be done with proper HTML parsing, but that will generate a lot more allocations and general processing overhead, so while probably more formally correct it's not my favourite answer for finding elements in this circumstance. With that in mind we can define expressions to find links, and to extract the dates:
private static readonly Regex _links = new Regex("<a\\s?(?<attrs>.*?)>(?<inner>.*?)</a>\\s?", RegexOptions.Compiled | RegexOptions.IgnoreCase);
private static readonly Regex _date = new Regex("until=\"(?<date>.*?)\"", RegexOptions.Compiled | RegexOptions.IgnoreCase);
The
_links
expression finds any
<a></a>
element and extracts its attributes and its contained content. And the
_date
expression finds the
until
attribute and extracts its value.
The code will need some state as it works. It'll need to track the content getting injected into the footnote that describes changes. It will need to track if any changes which need saving were made. And it will need to fetch the raw content from the input document. The first two of those are trivial, and Statiq provides convenient helper methods on
IDocument
to let you fetch the underlying content:
var footnoteToAppend = string.Empty; var hasChanged = false; var content = await input.GetContentStringAsync();
Then comes the more fun stuff:
var links = _links.Matches(content);
foreach(Match link in links)
{
var attrs = link.Groups["attrs"].Value;
var date = _date.Match(attrs);
if(date.Success)
{
var txt = date.Groups["date"].Value;
if(DateTime.TryParse(txt, out DateTime parsedDate))
{
if(parsedDate.Date < DateTime.Now.Date)
{
// remove link and return
content = content.Replace(link.Value, link.Groups["inner"].Value + "<a class=\"expired\" href=\"#expired\">**</a> ");
hasChanged = true;
footnoteToAppend += $"<li>{link.Value}</li>";
}
else
{
// remove until="??" and return
content = content.Replace($" {date.Value}", "");
hasChanged = true;
}
}
}
}
The code can iterate over the set of links that the the first regular expression discovers. And for each one it can try to parse out the date from the found attributes. If the date gets matched, it can be checked to see if its passed or not.
In the first highlighted block above it checks the parsed dates. For dates which have passed, the content of the post needs to change to replace the original
<a/>
element with the inner text that got matched before, and an anchor link to the footnote that will come later. And then the original link gets added to the footnote. That removes the expired link from the flow of the document, but keeps a copy in the footnote in case readers still want to look.
In the second highlighted block it deals with removing the
until
attribute if the link itself was not expired. I made up that attribute, so it's not valid HTML and it shouldn't be published in the final page. This only needs to happen if the overall link is staying in the page though.
Note that in both cases, when changes get made to the content it sets the
hasChanged
flag. That helps the code decide if it needs to replace Statiq's current document with the revised content this code is creating. For the majority of pages this will not need to happen, as they won't have changed.
But once that loop is done and all the relevant links have been modified, the remainder of the updating can happen:
if(hasChanged)
{
if(footnoteToAppend.Length > 0)
{
content += "<blockquote><h4>Expired links</h4><div><a class=\"expired\" name=\"expired\">**</a> Some links in this page have expired. The originals are listed here, but they may no longer point to the correct content:</div><ol>" + footnoteToAppend + "</ol></blockquote>";
}
var mt = input.GetContentProvider().MediaType;
return input
.Clone(context.GetContentProvider(content, mt))
.Yield();
}
If we tracked any changes then the input needs to be replaced with new stuff. The changes made might involve having content for the footnote. In that case it adds the relevant wrapper mark-up to format the footnote, and then inserts the individual items recorded earlier into that. That gives a block at the end of the page explaining that the links got expired, and listing out the originals.
And then after that test completes, the code needs to return the updated document. It grabs the correct media type (as that's important, and doesn't seem to be kept otherwise - and if it's not supplied, the resulting page loses all the surrounding Razor layout and formatting) and then it clones the input document passing in the changed content and the old media type. That insures further processing in the system will act on the new content only. The
yield
here returns the changed document to Statiq's runtime, where it will replace the old one for this page.
And with that, the only other change necessary was a little bit of CSS tweaking to make the links to the footnote look right:
a.expired {
vertical-align: super;
font-size: smaller;
text-underline-offset: -0.3em;
text-decoration: none !important;
}
a.expired[href] {
text-decoration: underline !important;
}
(This is likely not good CSS - but it was what I needed to get the right result for now)
If found using the
<sup></sup>
element to create the superscript footnote links tended to cause some odd whitespace behaviour. It was easier to have a plain link which uses CSS to make it superscript and small, instead of this element.
url copied!
So with that code in place, it's time for some test data. I created a test page with some testing content in it. The important bit was this, but I wrapped some more general content around it to make sure the test was valid:
## Test links: * Firstly, a link which <span class="rx">expired yesterday<a class="expired" href="#expired">**2</a><a name="removed2"></a><span></span>​</span> . * Here's a paragraph with a link that <span class="rx">expires tomorrow<a class="expired" href="#expired">**3</a><a name="removed3"></a><span></span>​</span> . * This link <span class="rx">expires today<a class="expired" href="#expired">**4</a><a name="removed4"></a><span></span>​</span> .
Publishing that page looks good:
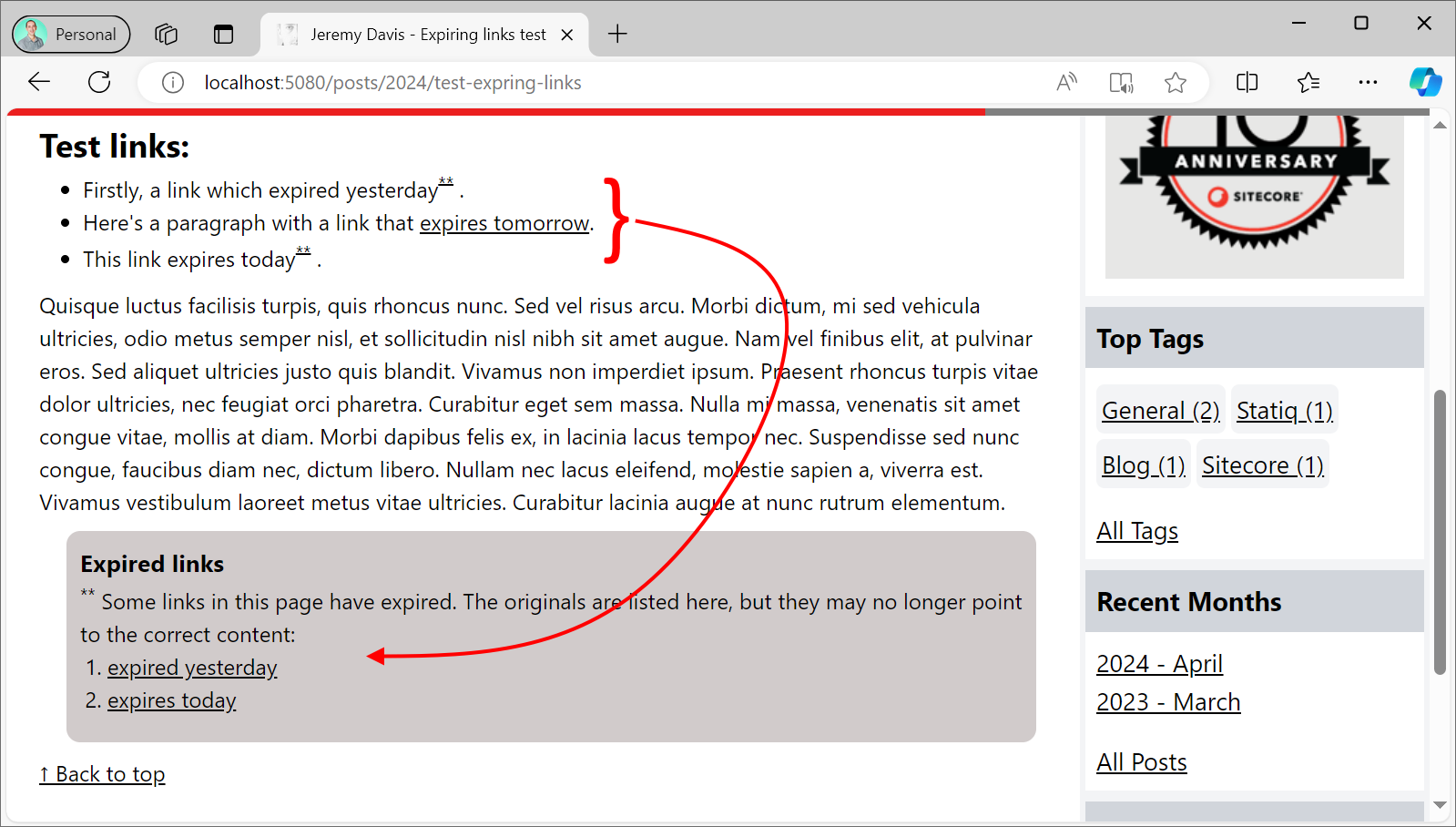
The "expires today" and "expires yesterday" links have been correctly removed from the page flow, and put in the footnote. But the "expires tomorrow" link is still shown in the page flow. And you can click on the footnote indicators next to the removed links, to be taken to the footnote on longer pages. And when I look at the published mark-up for the "expires tomorrow" link, it no longer has the
until
attribute:
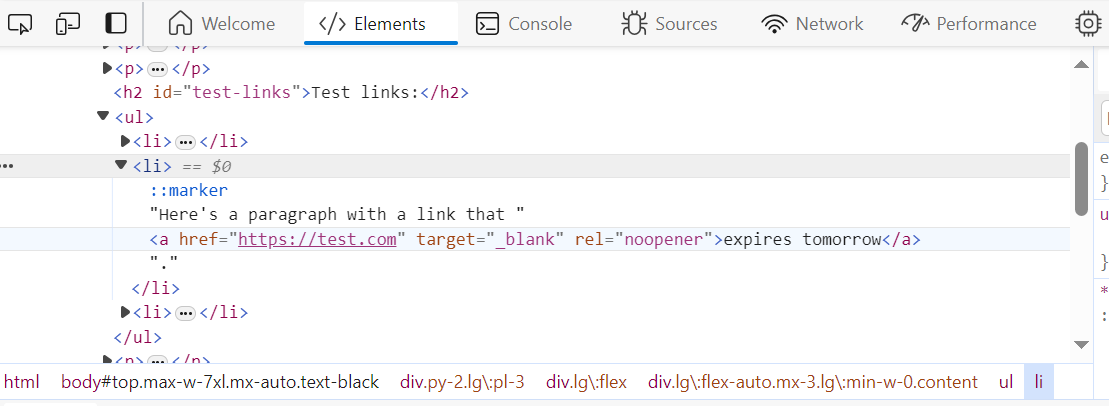
That looks like success to me.
url copied!
It's a prototype, so I suspect I need to do a bit more here. I've created a gist of the basic code, in case that's of use to anyone. But I think it could do with some refactoring and refinement when I have a chance.
The key thing I'd like to change is to make the content for the footnote link and the footnote itself configurable. It's fine for a hacky prototype to hard-code that into the processor, but best to find a better location for the longer term.
In writing this up, I realise one edge case that this code doesn't cover is links which are in the snippet shown on listing pages. Making links expire there may be more of a challenge. But I'm tempted to make a validator so my editor says "don't put expiring links here" in the short term, as that would be the easiest fix for a potentially tricky case.
And while this general approach works, I think it could probably have better UI for people browsing the site. On longer pages it might make sense to make the individual footnote links connect to specific entries in the main footnote, and vice-versa? So you can move back and forth?
So I'll tinker with further changes later...
↑ Back to topExpired links:
** Some links in this page have expired. The originals are listed here, but they may no longer point to working pages or the correct content:

